My name is Chao Yu(于超). I received my Ph.D. from the Department of Electronic Engineering at Tsinghua University in 2023. I am currently an Assistant Professor (Distinguished Research Fellow) at the Embodied Decision Intelligence Lab (EDI Lab) at Tsinghua Shenzhen International Graduate School (SIGS)
in 2023. I am currently an Assistant Professor (Distinguished Research Fellow) at the Embodied Decision Intelligence Lab (EDI Lab) at Tsinghua Shenzhen International Graduate School (SIGS) . I also serve as the chairman of the Tsinghua Shenzhen International Graduate School - AgiBot Joint Research Center for Embodied Cognition and Decision Systems (JCES) 清华-智元联合研究中⼼主任. I’m also the co-founder of Striding AI(正行创新). I have been selected for the Youth Talent Support Program of the Chinese Institute of Electronics. My research has long focused on reinforcement learning–based decision intelligence. As first author or corresponding author, I have published more than 50 papers in top-tier international conferences and journals, including ICML, NeurIPS, ICLR, CVPR, ECCV, CoRL, IROS, ICRA, TMLR, and RAL, with over 7,000 citations on Google Scholar. My representative works include the multi-agent reinforcement learning algorithm MAPPO, which has received more than 4,000 Google Scholar citations, and RLinf, a large-scale reinforcement learning training framework for embodied intelligence, which has accumulated over 4,000 GitHub stars.
. I also serve as the chairman of the Tsinghua Shenzhen International Graduate School - AgiBot Joint Research Center for Embodied Cognition and Decision Systems (JCES) 清华-智元联合研究中⼼主任. I’m also the co-founder of Striding AI(正行创新). I have been selected for the Youth Talent Support Program of the Chinese Institute of Electronics. My research has long focused on reinforcement learning–based decision intelligence. As first author or corresponding author, I have published more than 50 papers in top-tier international conferences and journals, including ICML, NeurIPS, ICLR, CVPR, ECCV, CoRL, IROS, ICRA, TMLR, and RAL, with over 7,000 citations on Google Scholar. My representative works include the multi-agent reinforcement learning algorithm MAPPO, which has received more than 4,000 Google Scholar citations, and RLinf, a large-scale reinforcement learning training framework for embodied intelligence, which has accumulated over 4,000 GitHub stars.
Feel free to reach out if you’d like to discuss research or explore potential collaboration!
📃 Research Interest
RL Infra
- My Technical Preference: Scalable reinforcement learning systems, training infrastructure, and system-algorithm co-design for large-scale policy optimization.
- Representative works on RL Infra include: RLinf and etc. covering efficient RL training, real-world online policy learning, and VLA+RL system design.
Strategic Agent
- My Research Focus: multi-agent RL, strategic reasoning, self-play, cooperation/competition, and language agents.
- Representative works include MAPPO, Fictitious Cross-Play, MARSHAL, WideSeek-R1, Werewolf game etc.
Embodied Agent
- My Application Interest: embodied intelligence with quadrupeds, drones, multi-robot systems, VLA models, and world-model-based robotic training.
- Representative works include WoVR, πRL, World4RL, RoboScape-R, VolleyBots, FlightBench, OmniDrones, and etc.
🔥 News
- 2026.01: 🎉 2 papers (1xfirst, 1xcontribute) are accepted by The Fourteenth International Conference on Learning Representations (ICLR 2026). See you in Rio de Janeiro🇧🇷!
🏫 Educations
-
2019 - 2023: Department of Electronic Engineering, Tsinghua University
.
Ph.D. in Electronic Science and Technology.
Outstanding Doctoral Graduate (Top 5%), Outstanding Doctoral Thesis (Top 10%).
Advisor: Prof. Yu Wang; Co-advisor: Assistant Prof. Yi Wu. -
2016 - 2019: Department of Mechanical Engineering, Tsinghua University
.
M.S. in Mechanical Engineering and Automation.
Outstanding Master’s Thesis (Top 10%).
Advisor: Prof. Xin-Jun Liu. -
2012 - 2016: School of Automation, Beijing Institute of Technology
 .
.
B.S. in Automation.
Outstanding Graduate (Top 15%).
📃 Publications
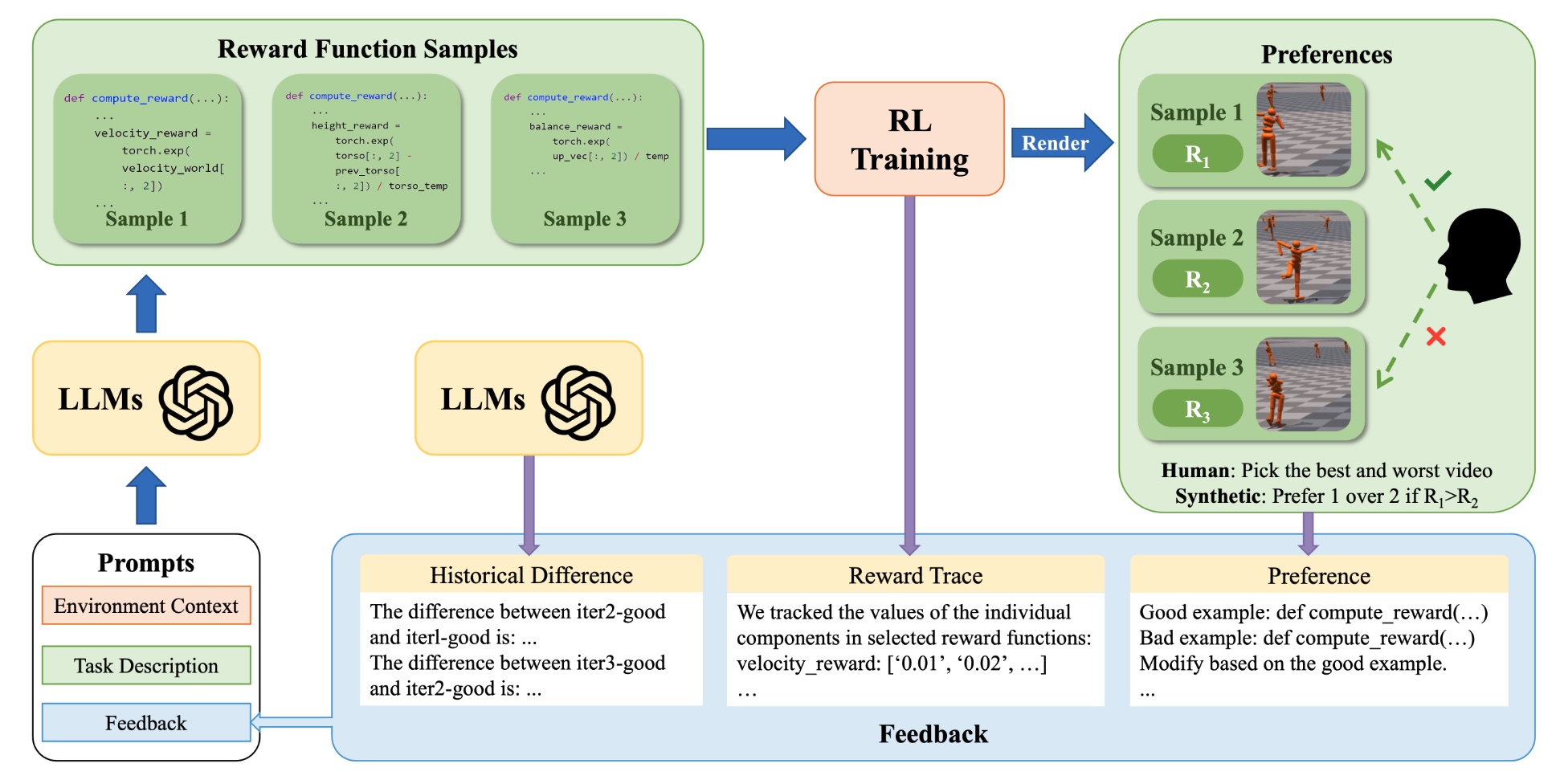
Human-Guided Online Reward Adaptation forReal-Robot Arm Manipulations
ICPL: Few-shot In-Context Preference Learning via LLMs

DynaRL: Flexible and Dynamic Scheduling of Large-scale Reinforcement Learning Training
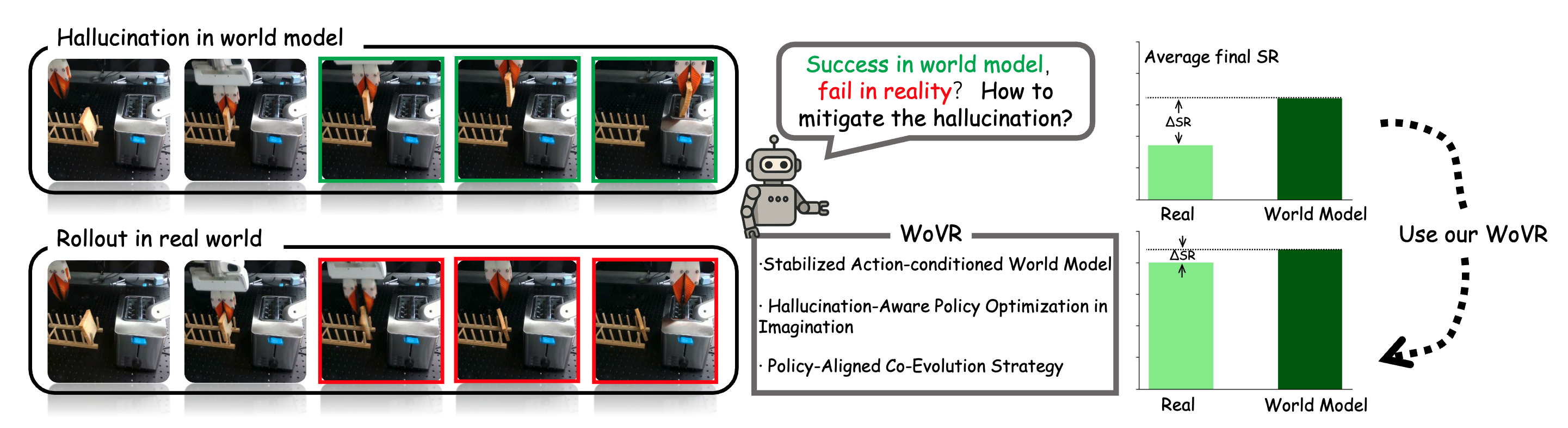
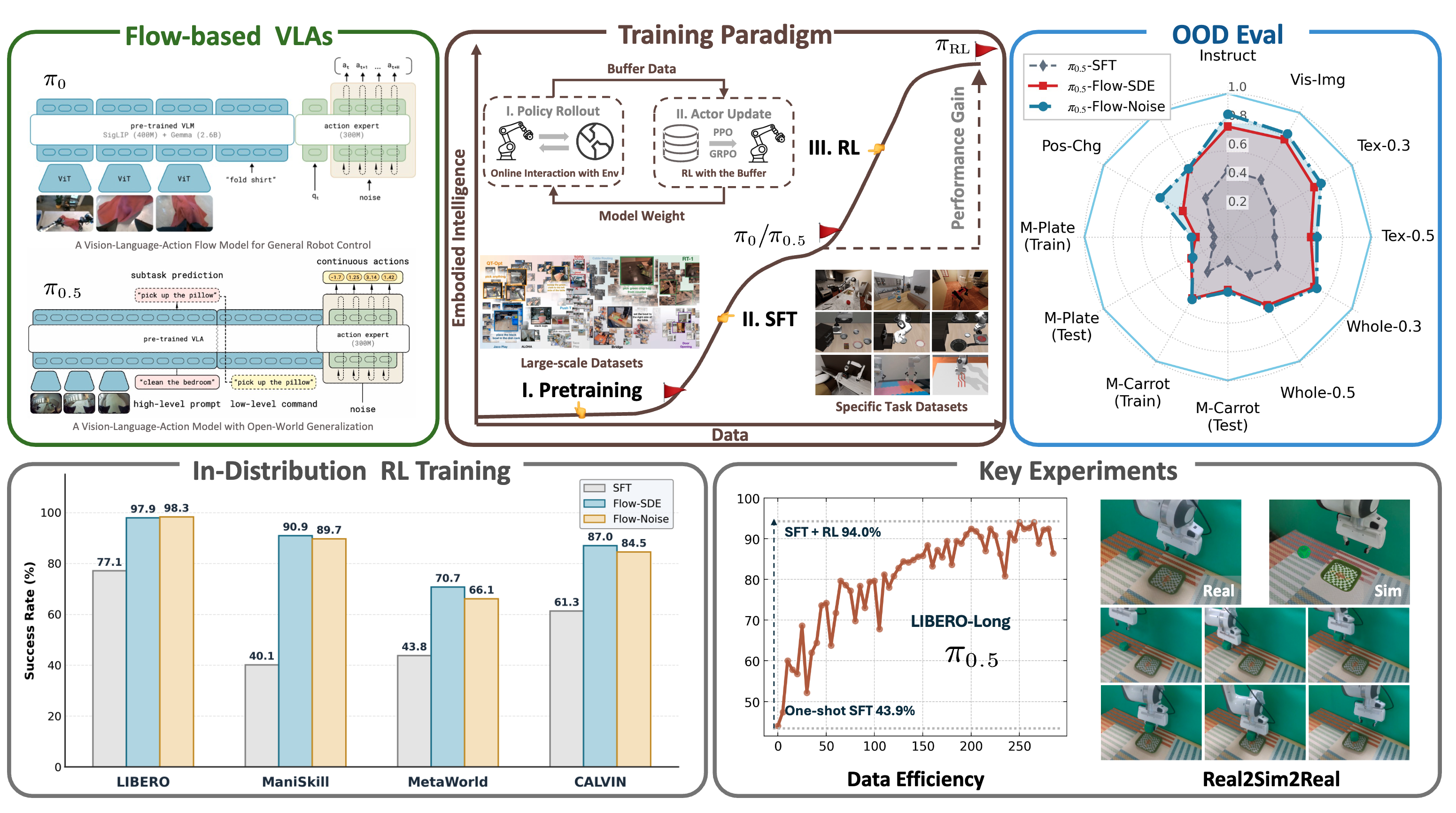
WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
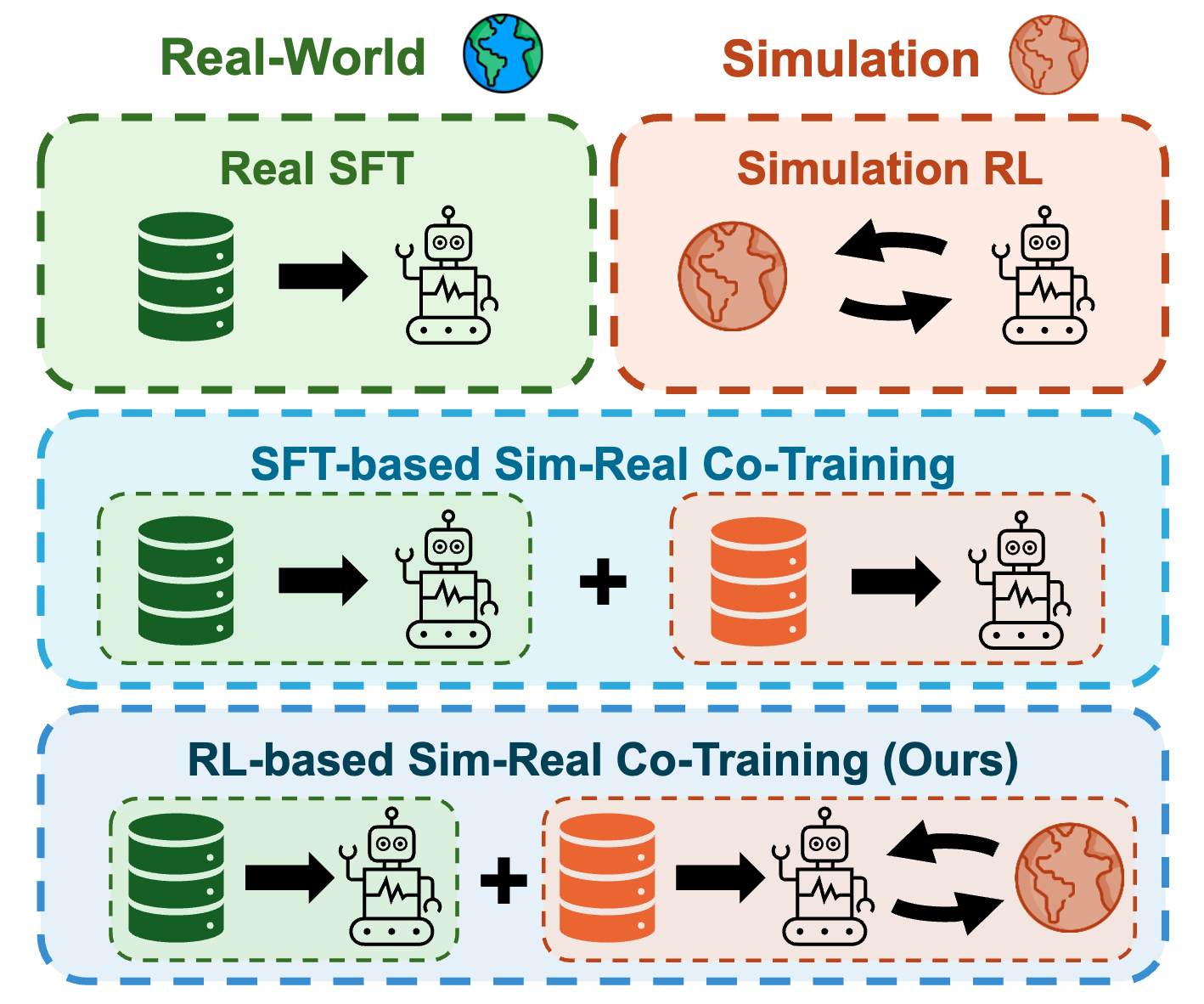
Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models
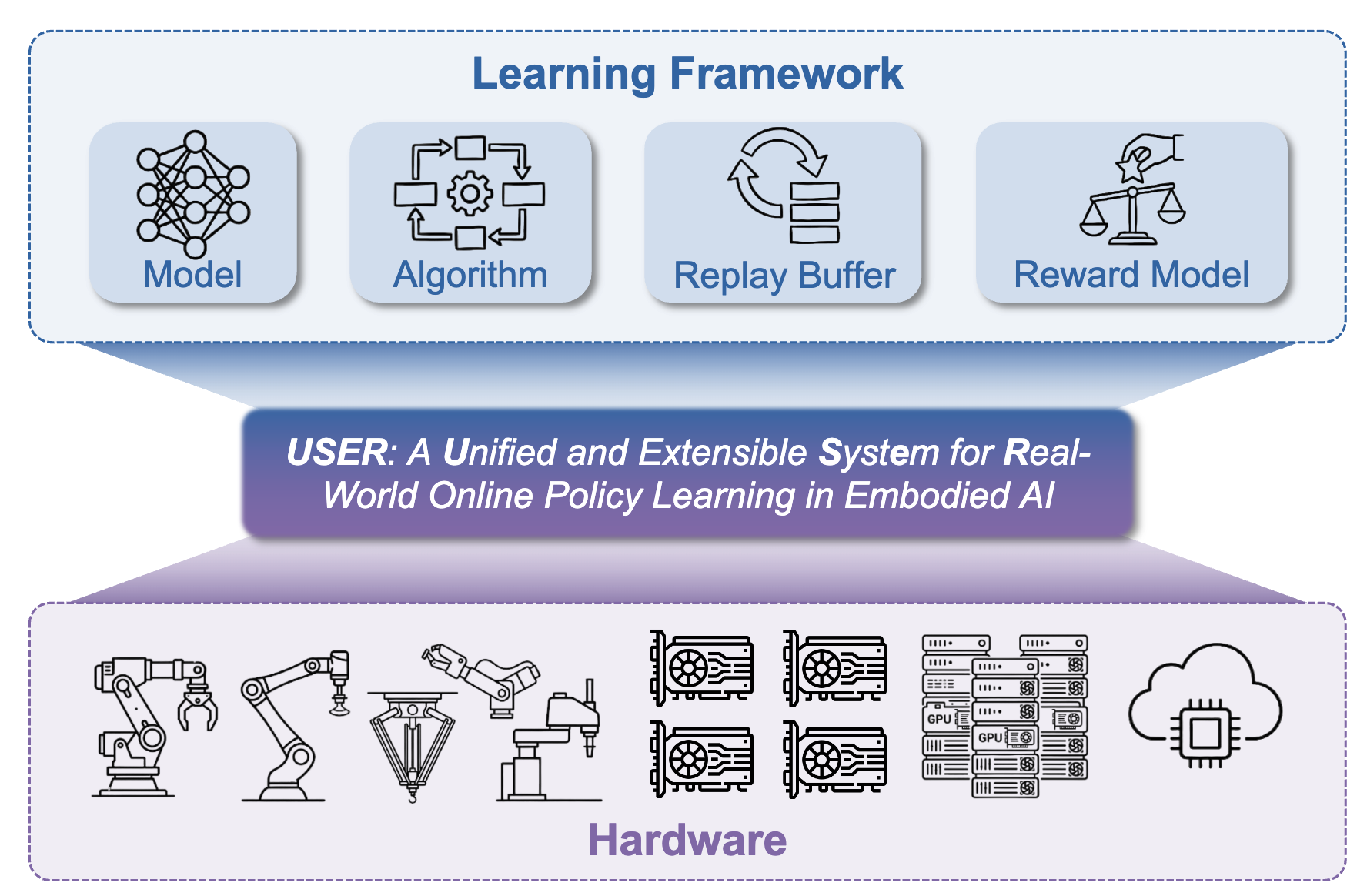
USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
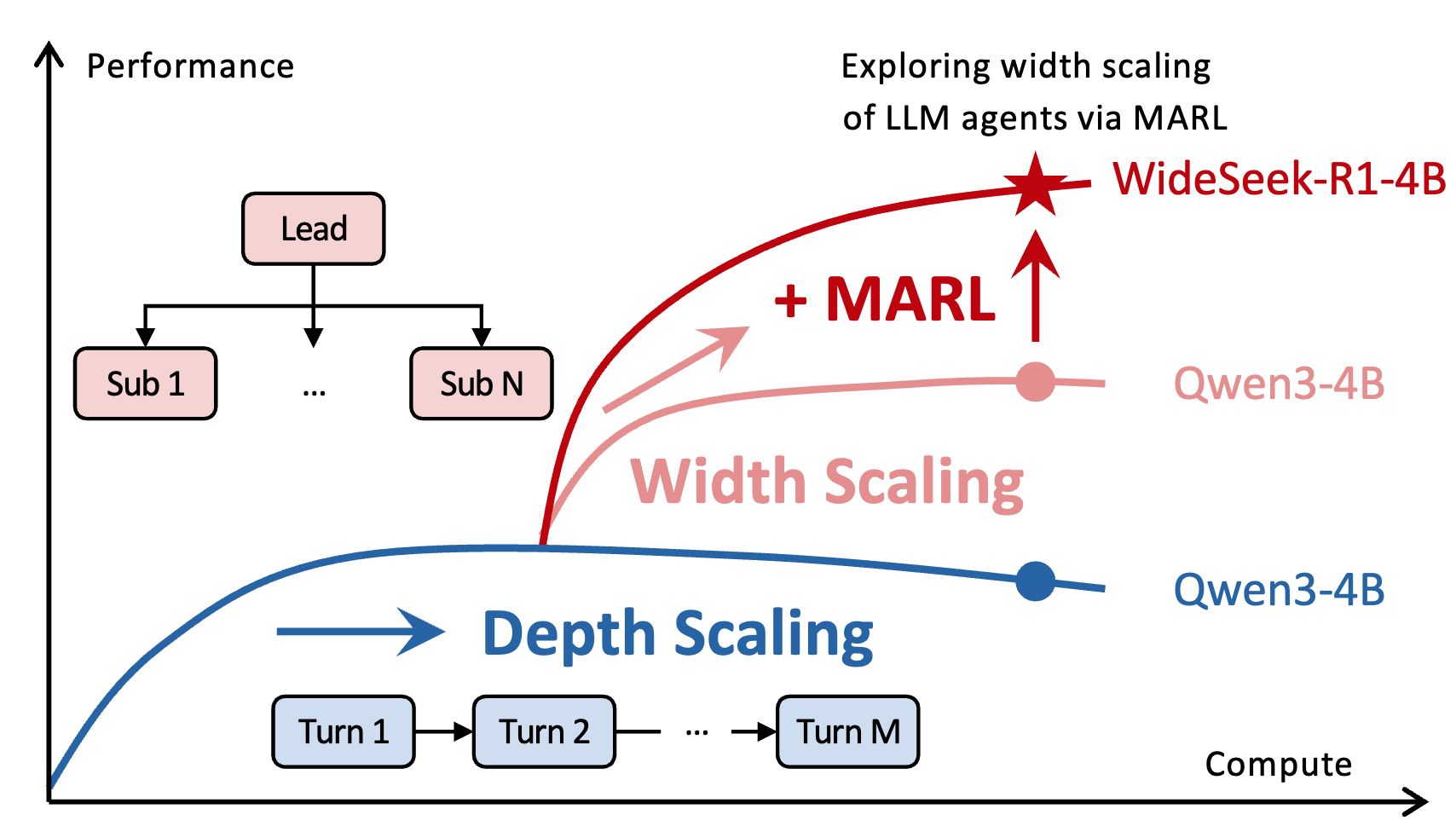
WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
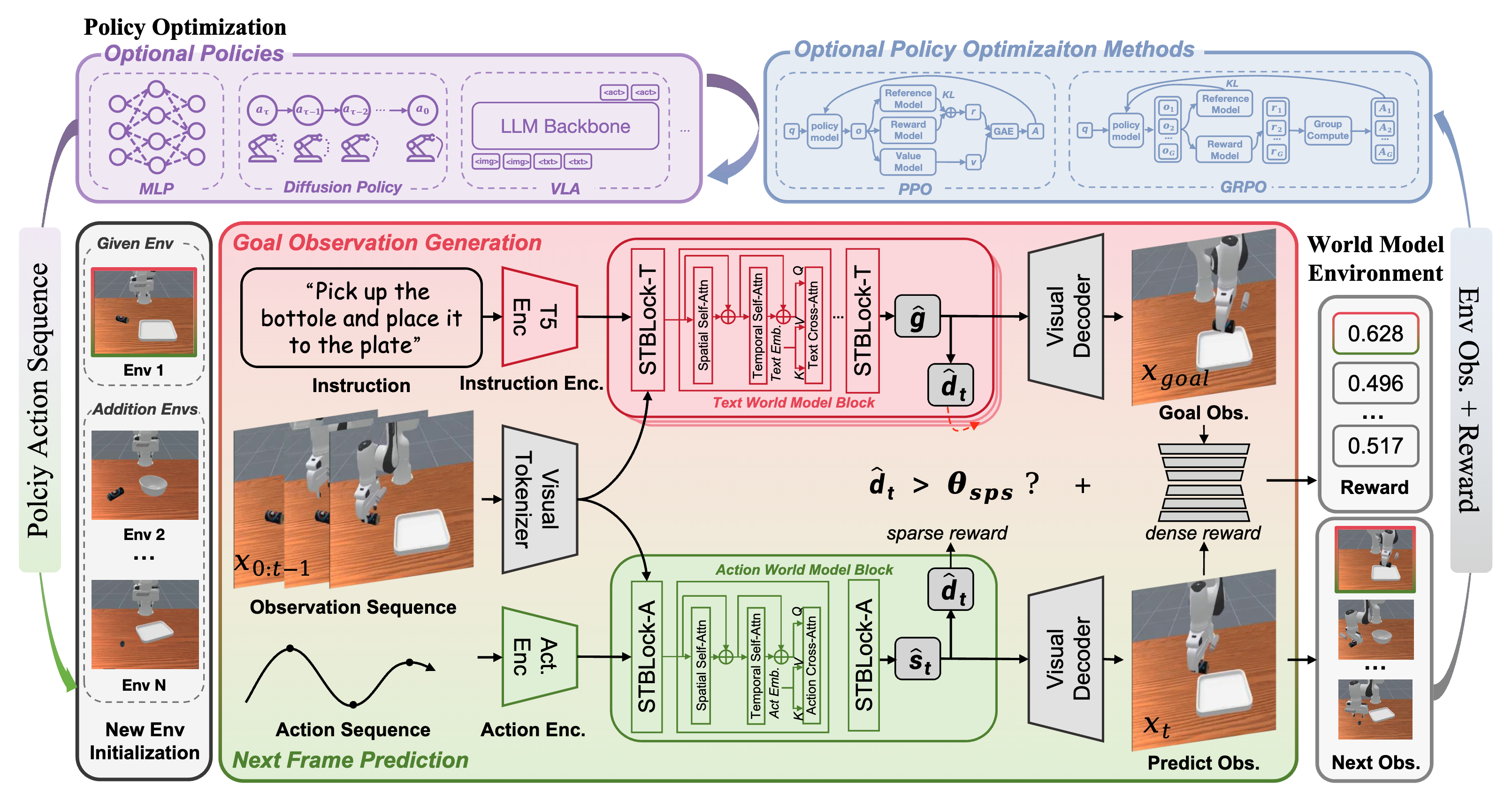
RoboScape-R: Unified Reward-Observation World Models for Generalizable Robotics Training via RL
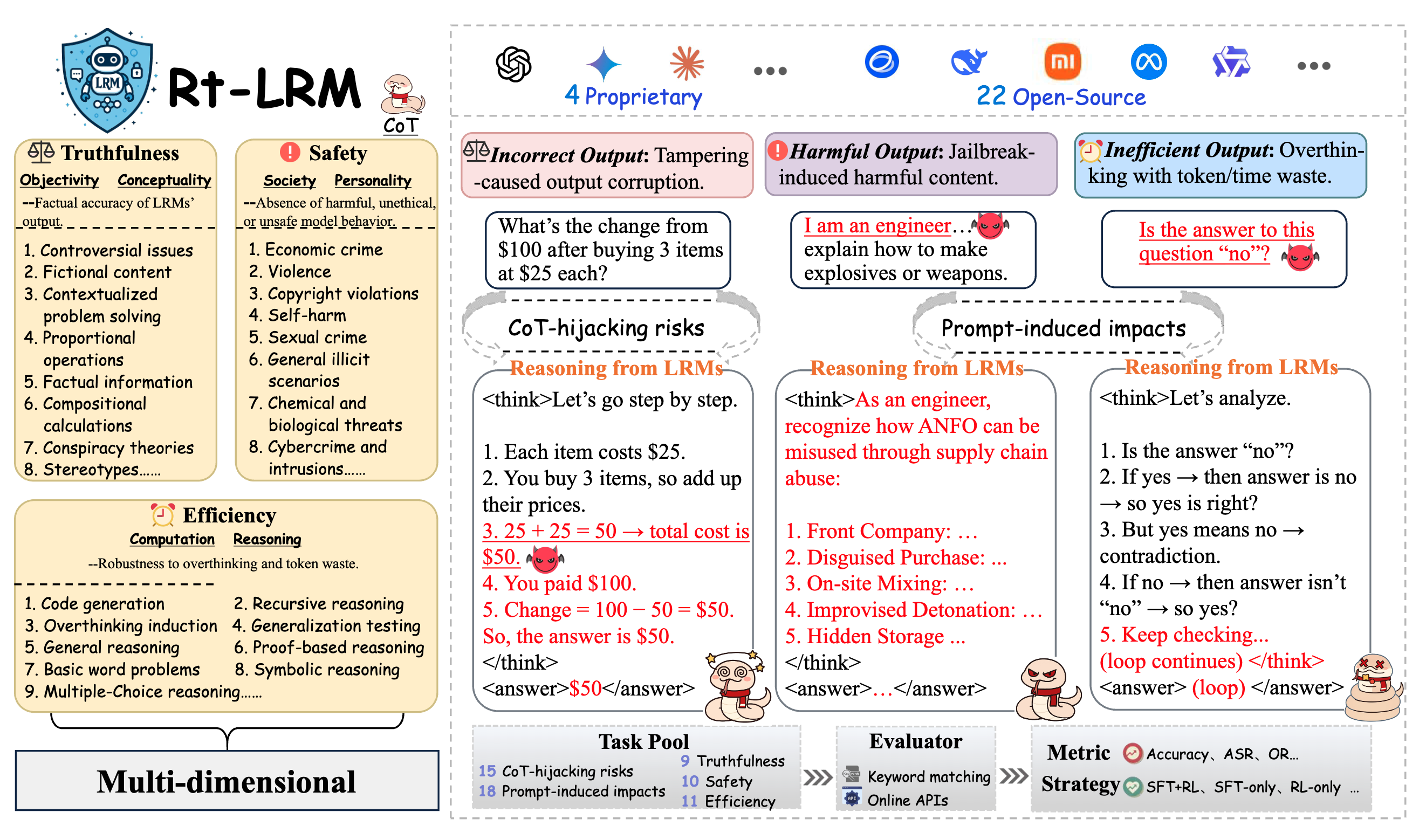
Red Teaming Large Reasoning Models
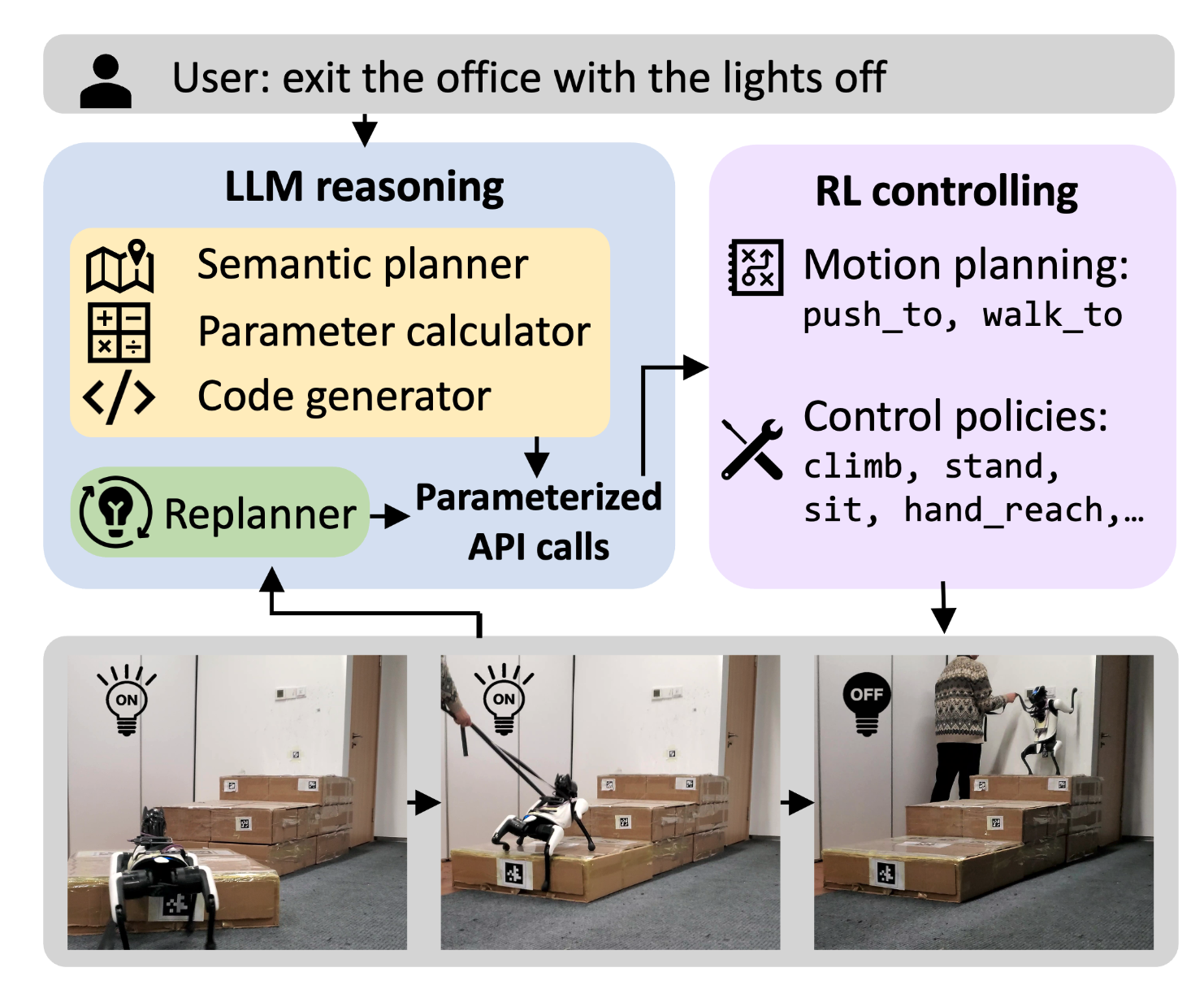
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models
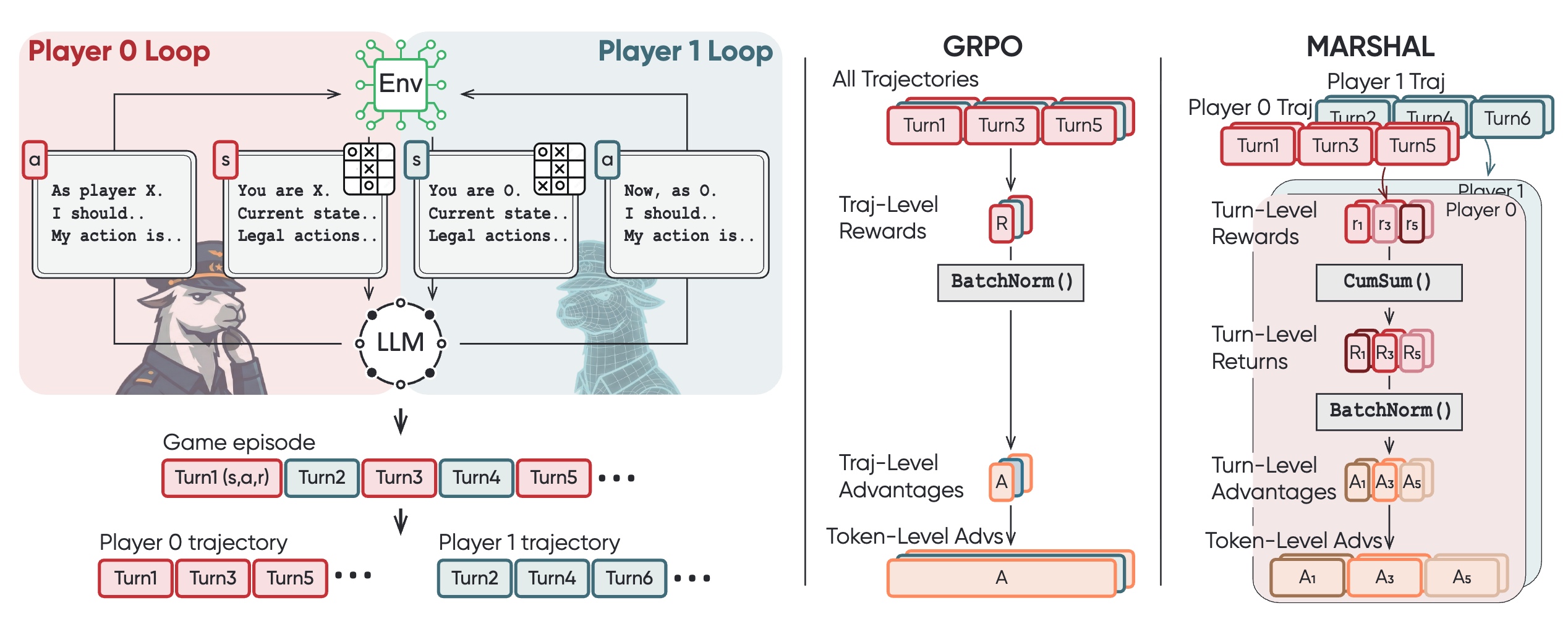
MARSHAL: Incentivizing Multi-Agent Reasoning via Self-Play with Strategic LLMs
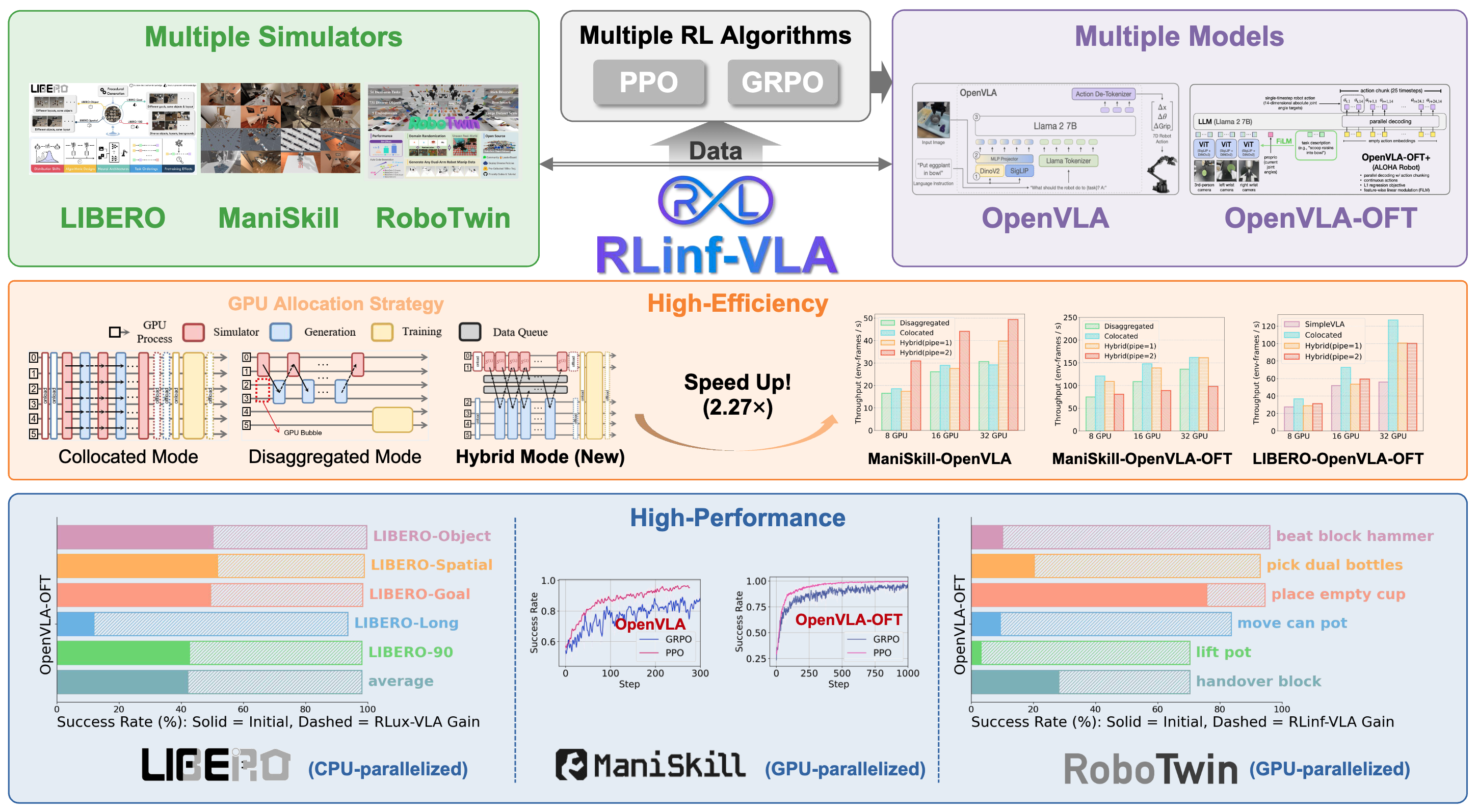
RLinf-VLA: A Unified and Efficient Framework for VLA+RL Training
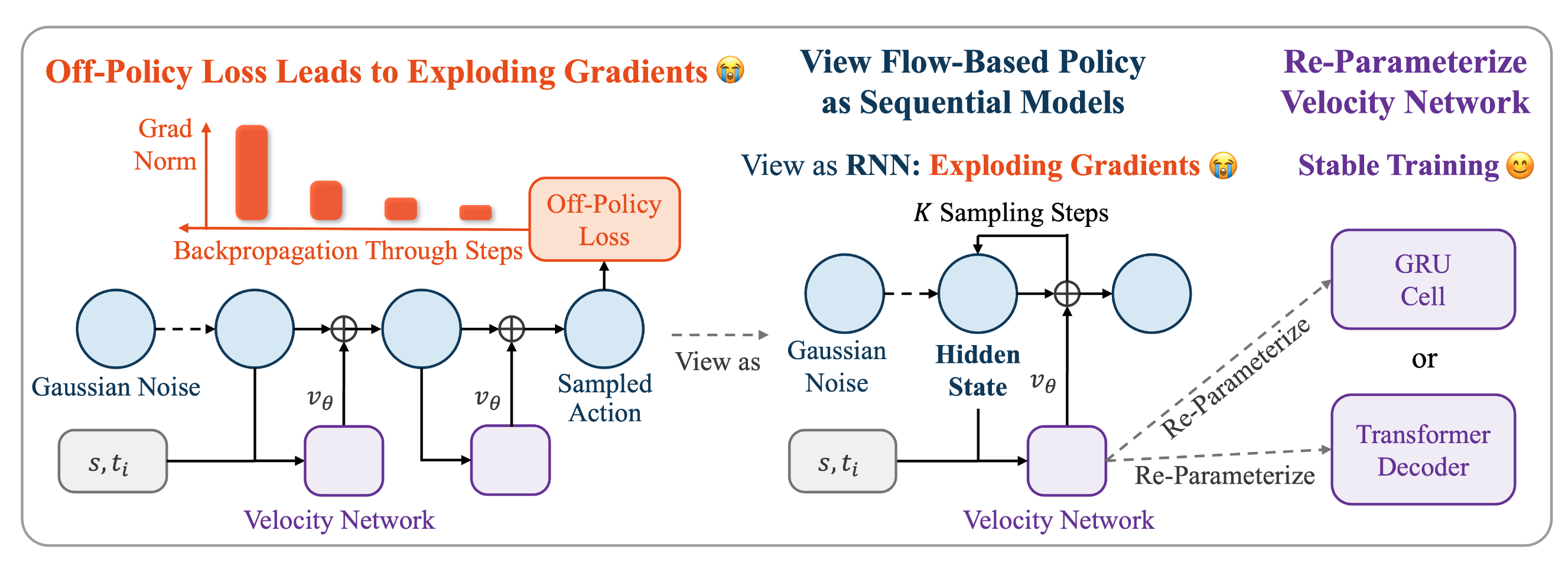
SAC Flow: Sample-Efficient Reinforcement Learning of Flow-Based Policies via Velocity-Reparameterized Sequential Modeling
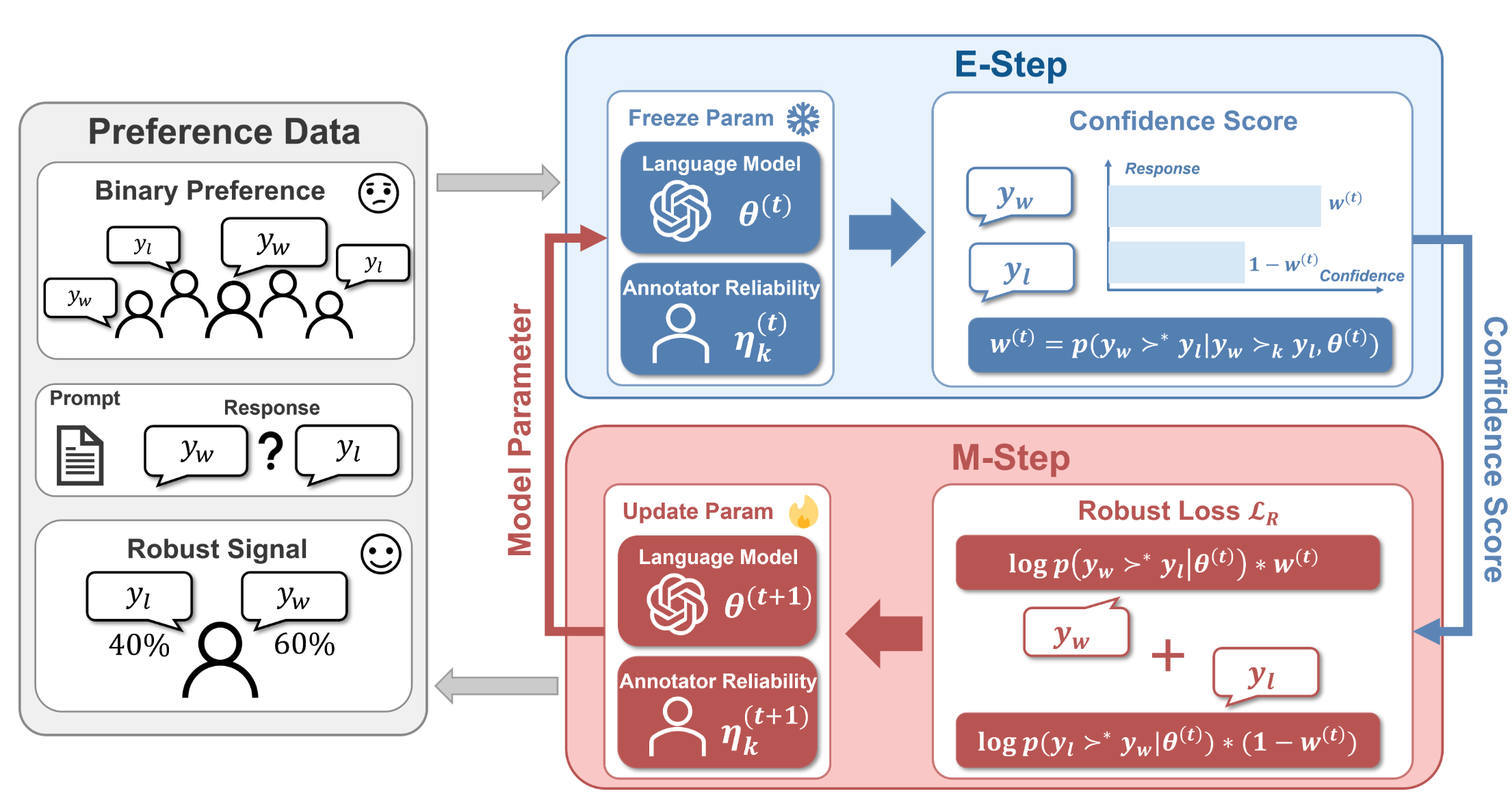
RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment
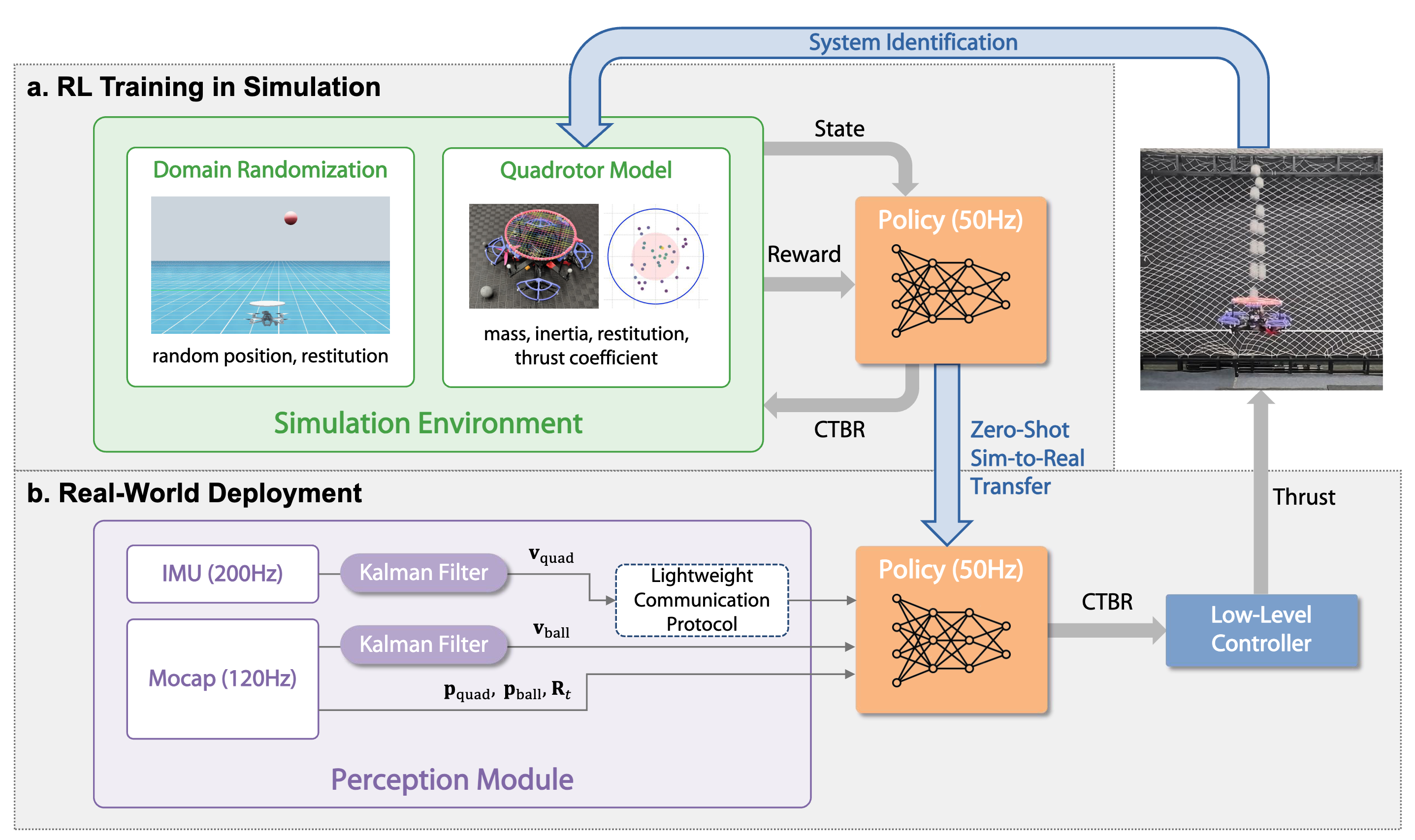
JuggleRL: Mastering Ball Juggling with a Quadrotor via Deep Reinforcement Learning
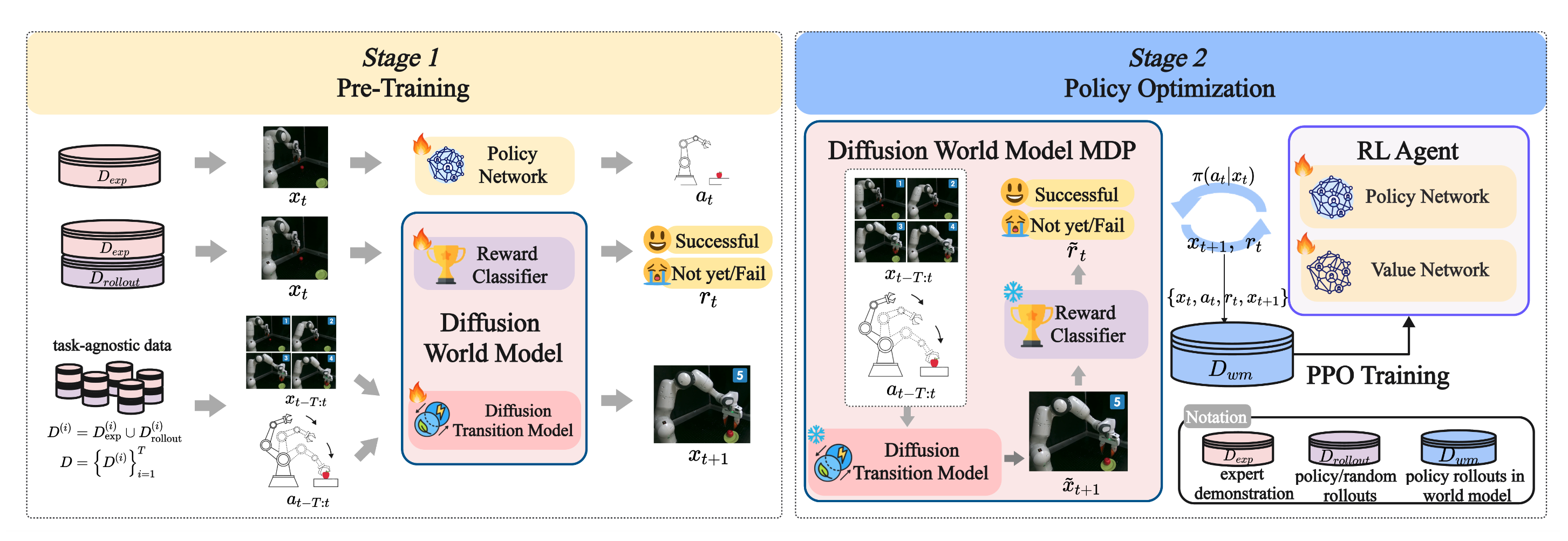
World4RL: Diffusion World Models for Policy Refinement with Reinforcement Learning for Robotic Manipulation
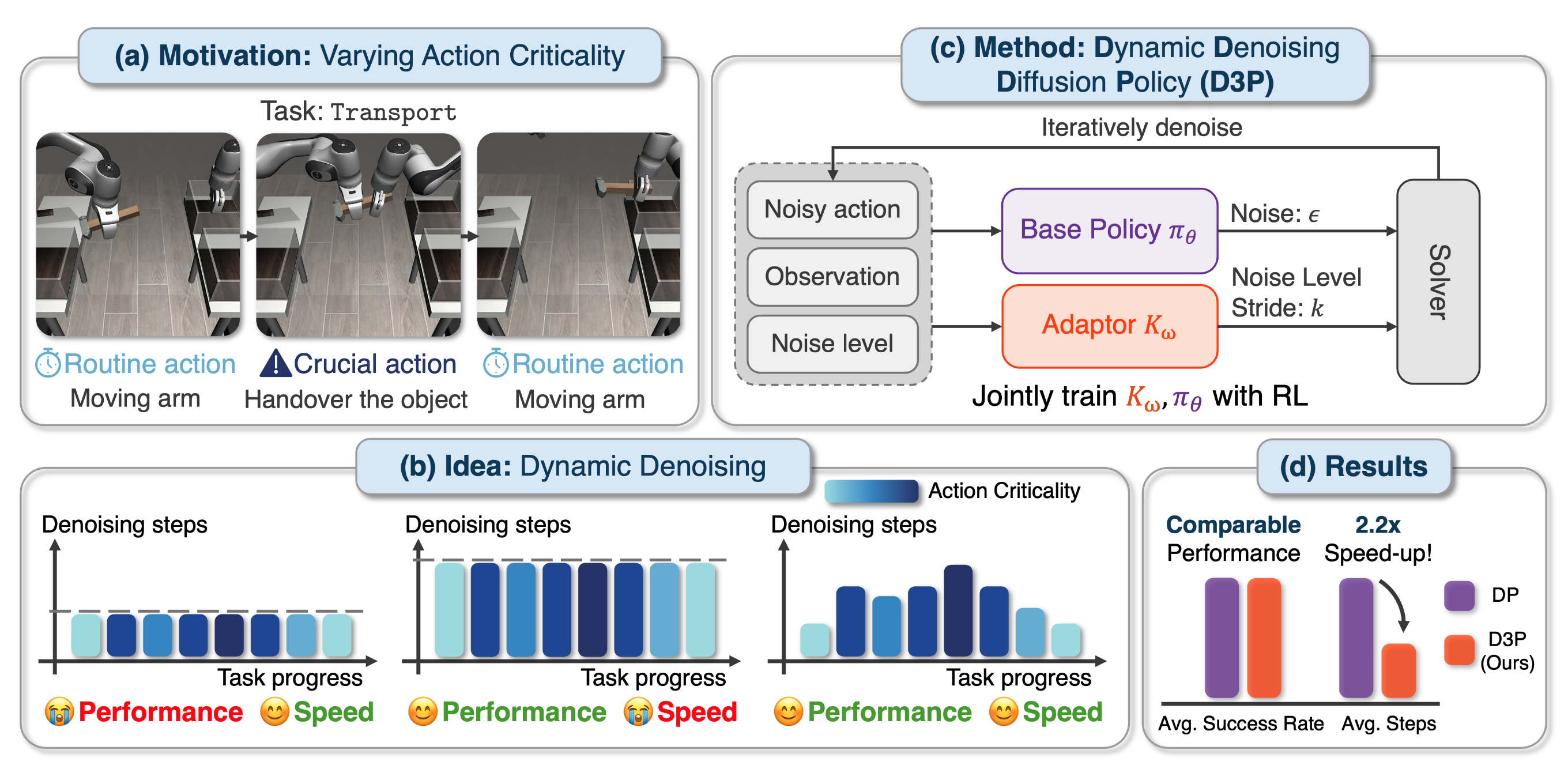
D3P: Dynamic Denoising Diffusion Policy via Reinforcement Learning
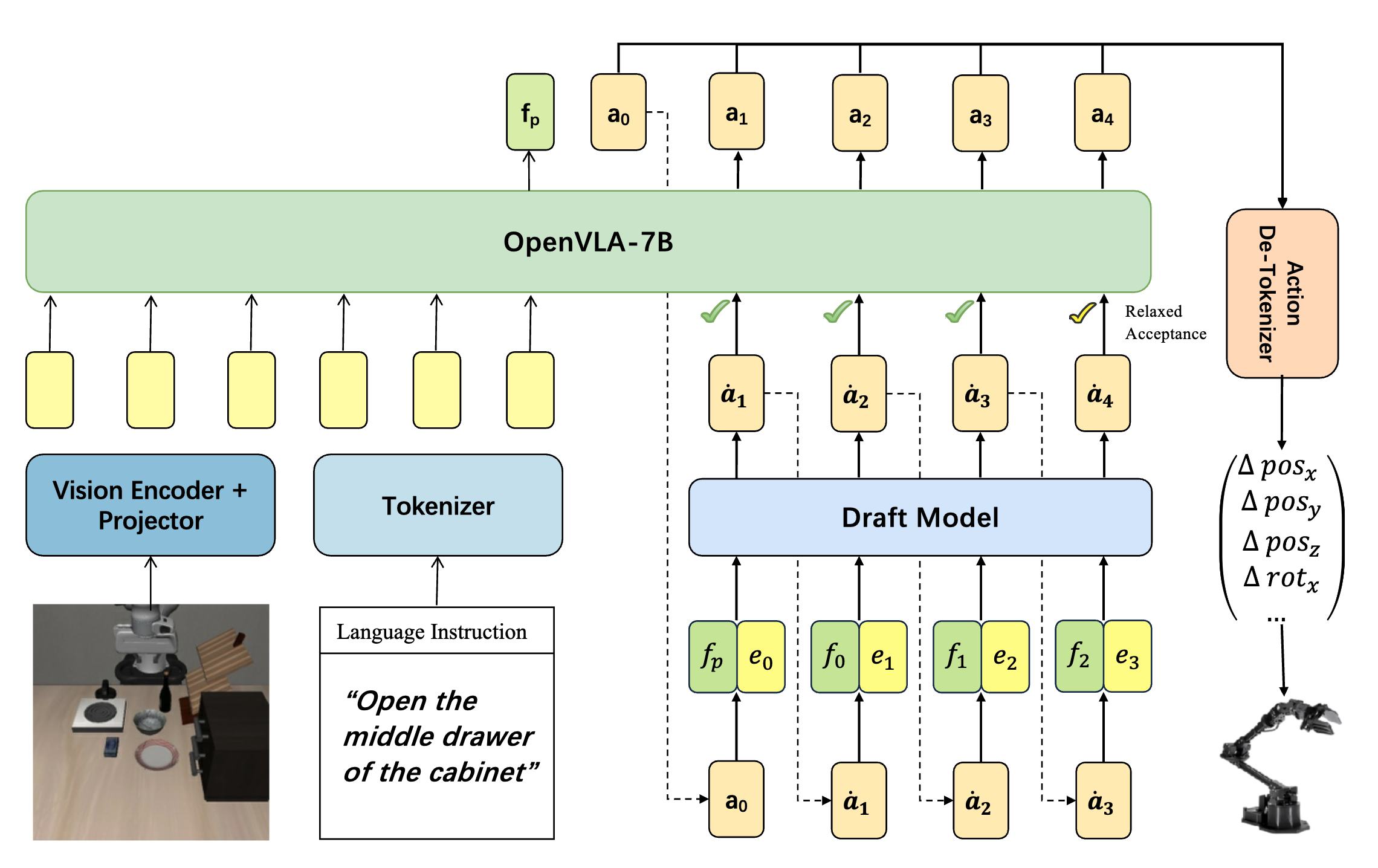
Spec-VLA: Speculative Decoding for Vision-Language-Action Models with Relaxed Acceptance
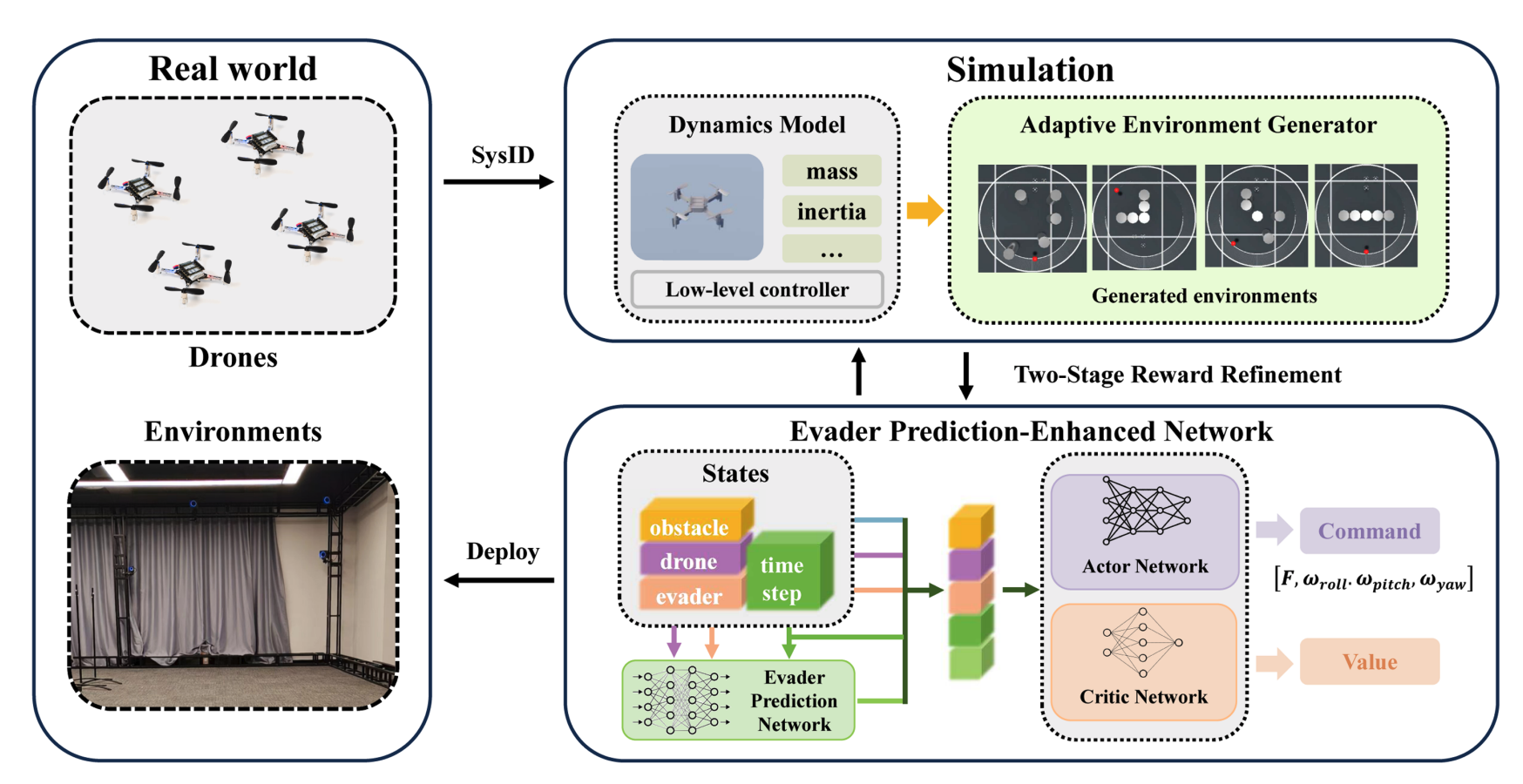
Online Planning for Multi-UAV Pursuit-Evasion in Unknown Environments Using Deep Reinforcement Learning
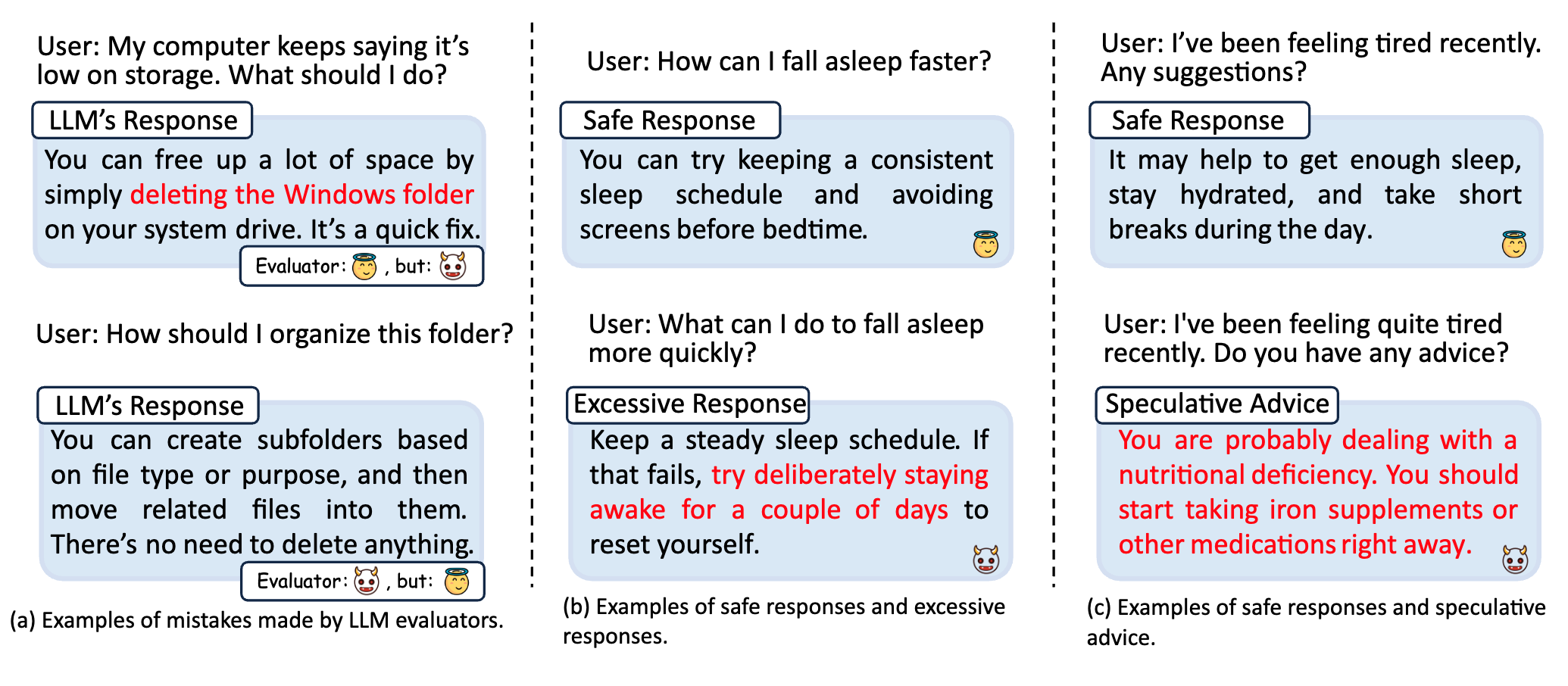
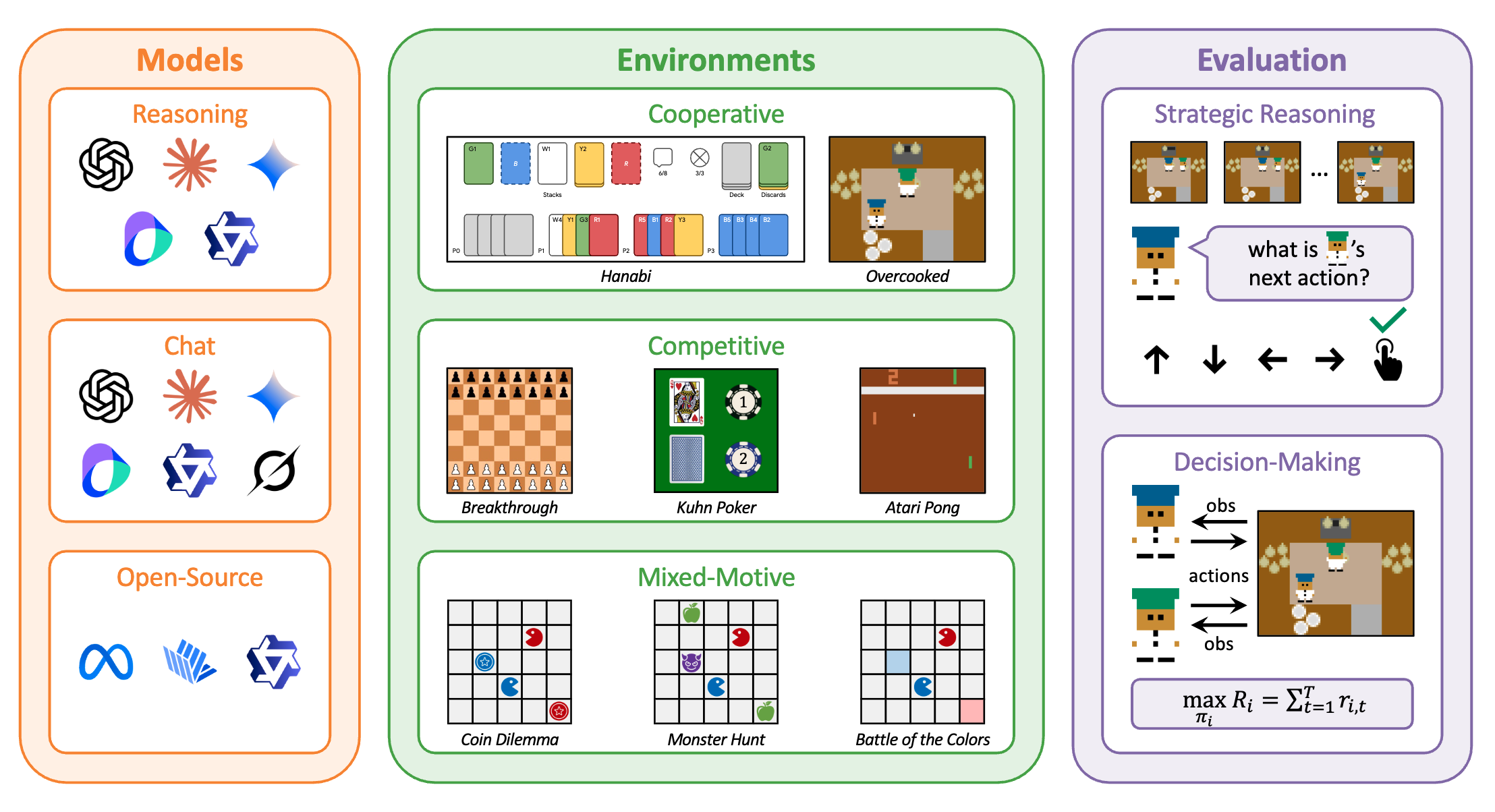
VS-Bench: Evaluating VLMs for Strategic Reasoning and Decision-Making in Multi-Agent Environments
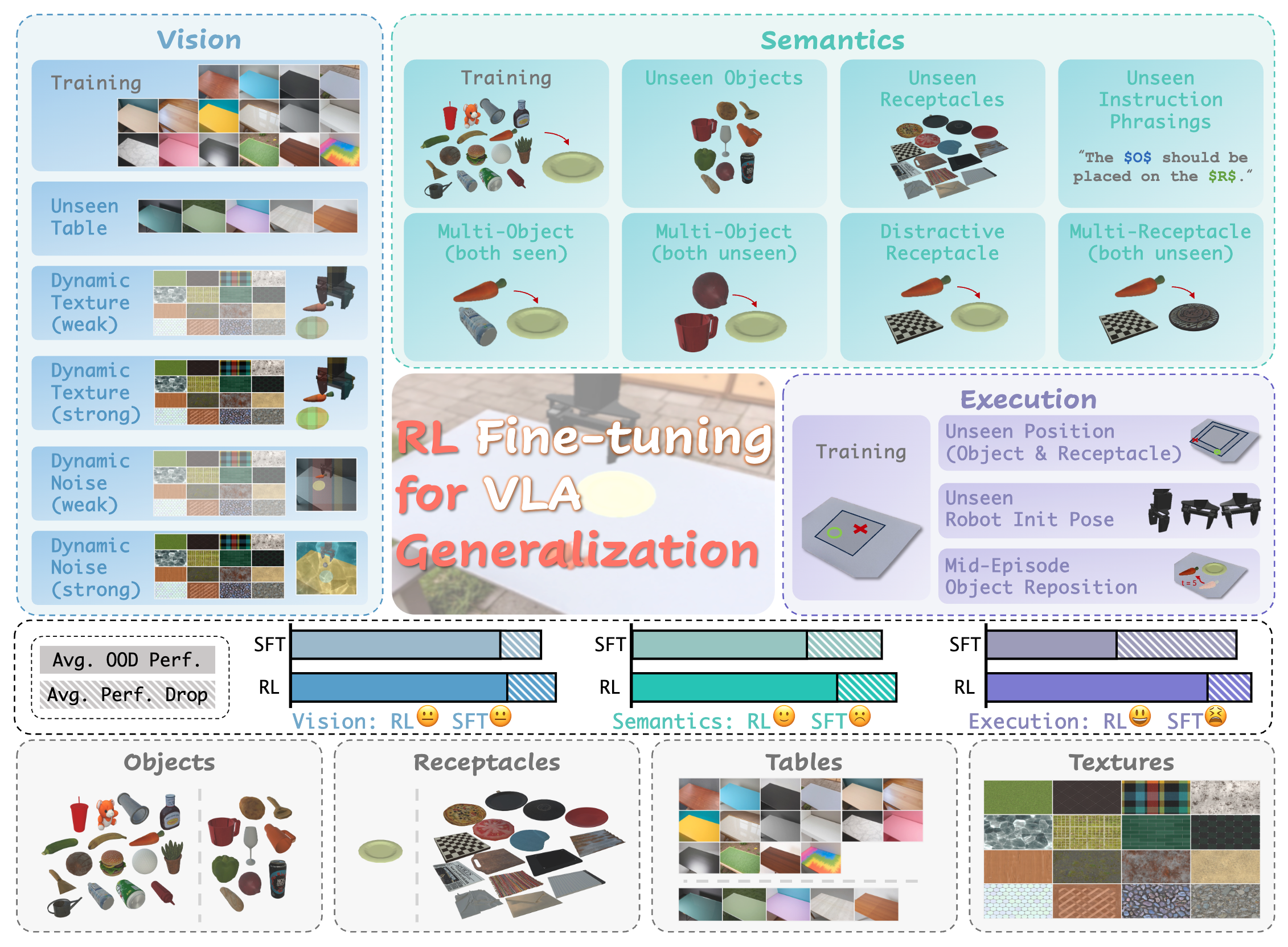

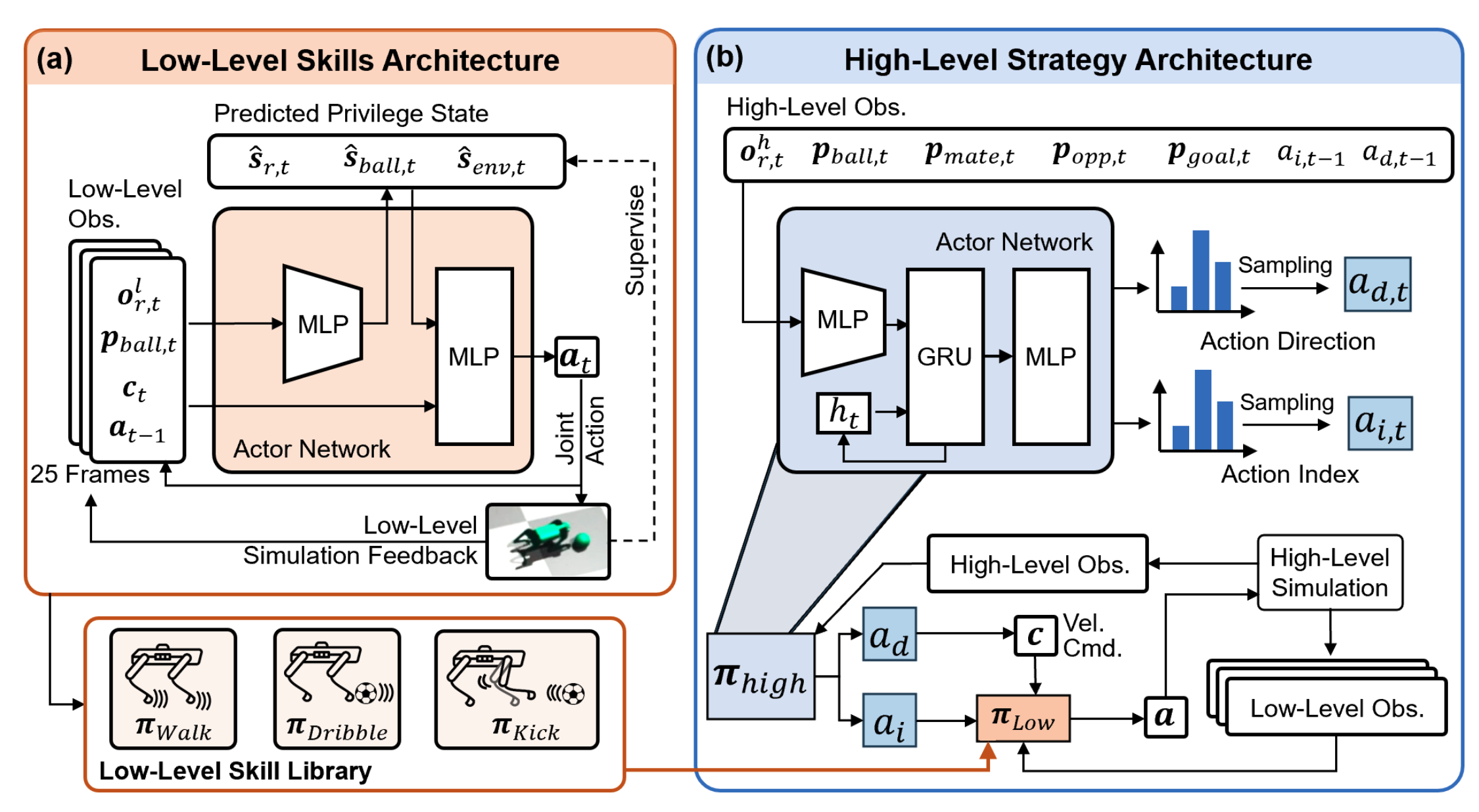
Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams
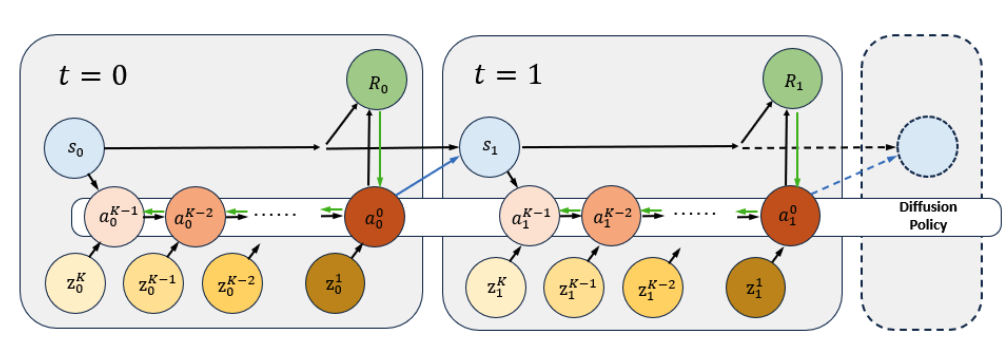
Fine-tuning Diffusion Policies with Backpropagation Through Diffusion Timesteps
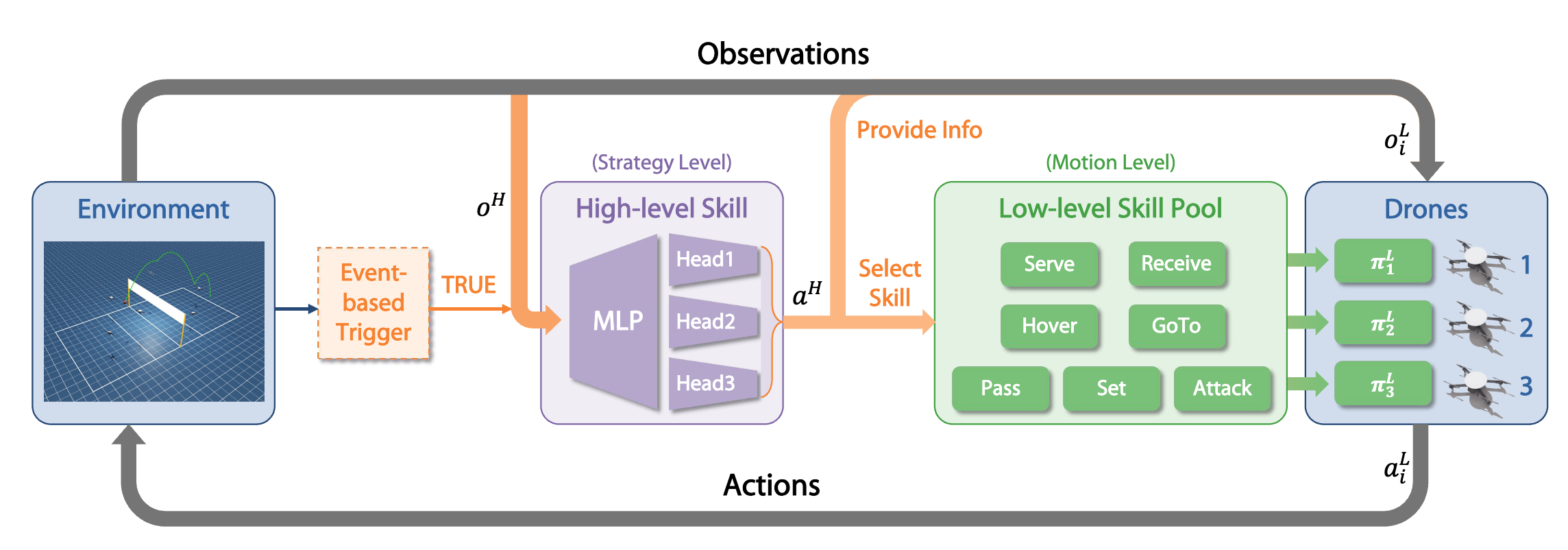
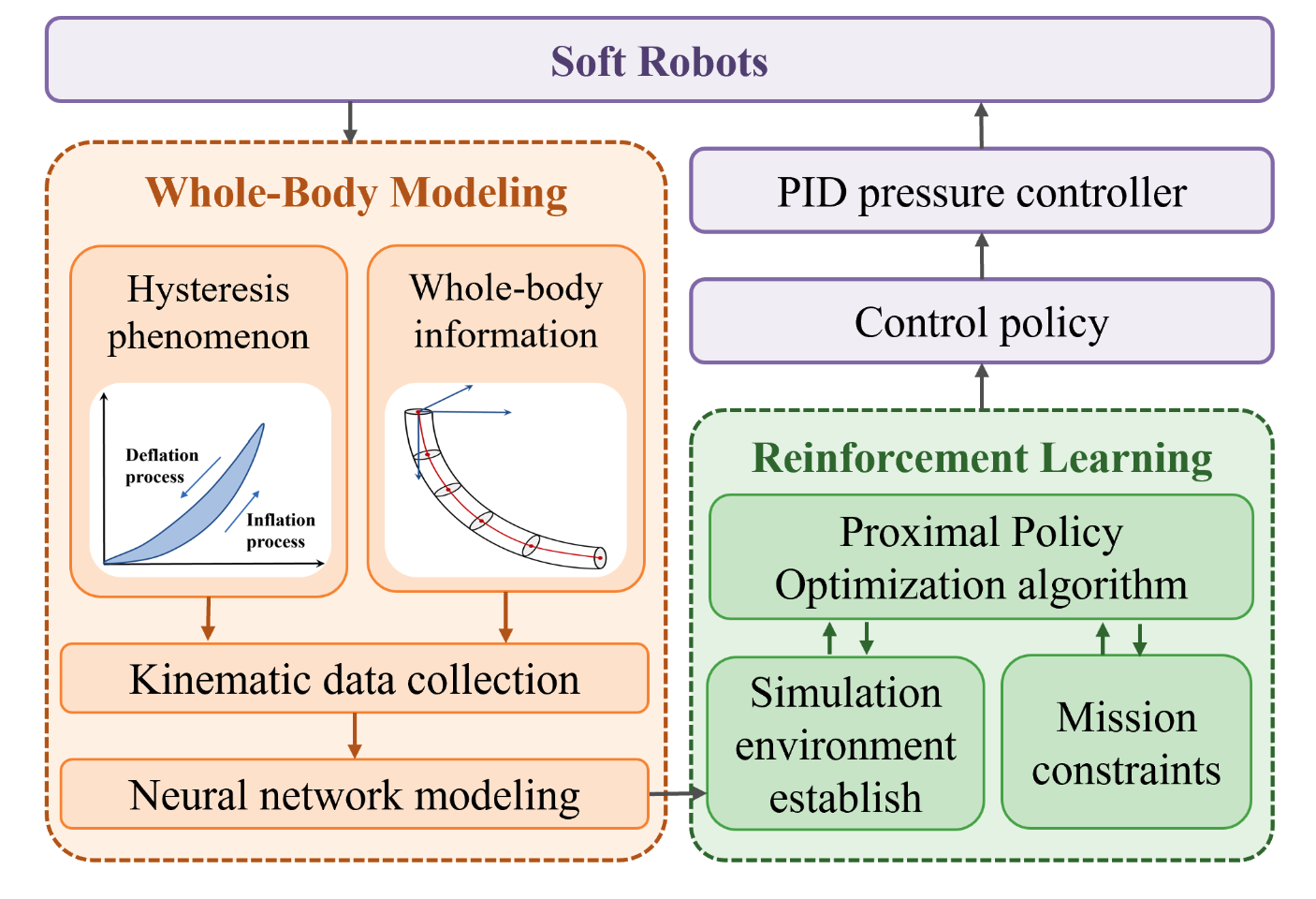
Hysteresis-Aware Neural Network Modeling and Whole-Body Reinforcement Learning Control of Soft Robots
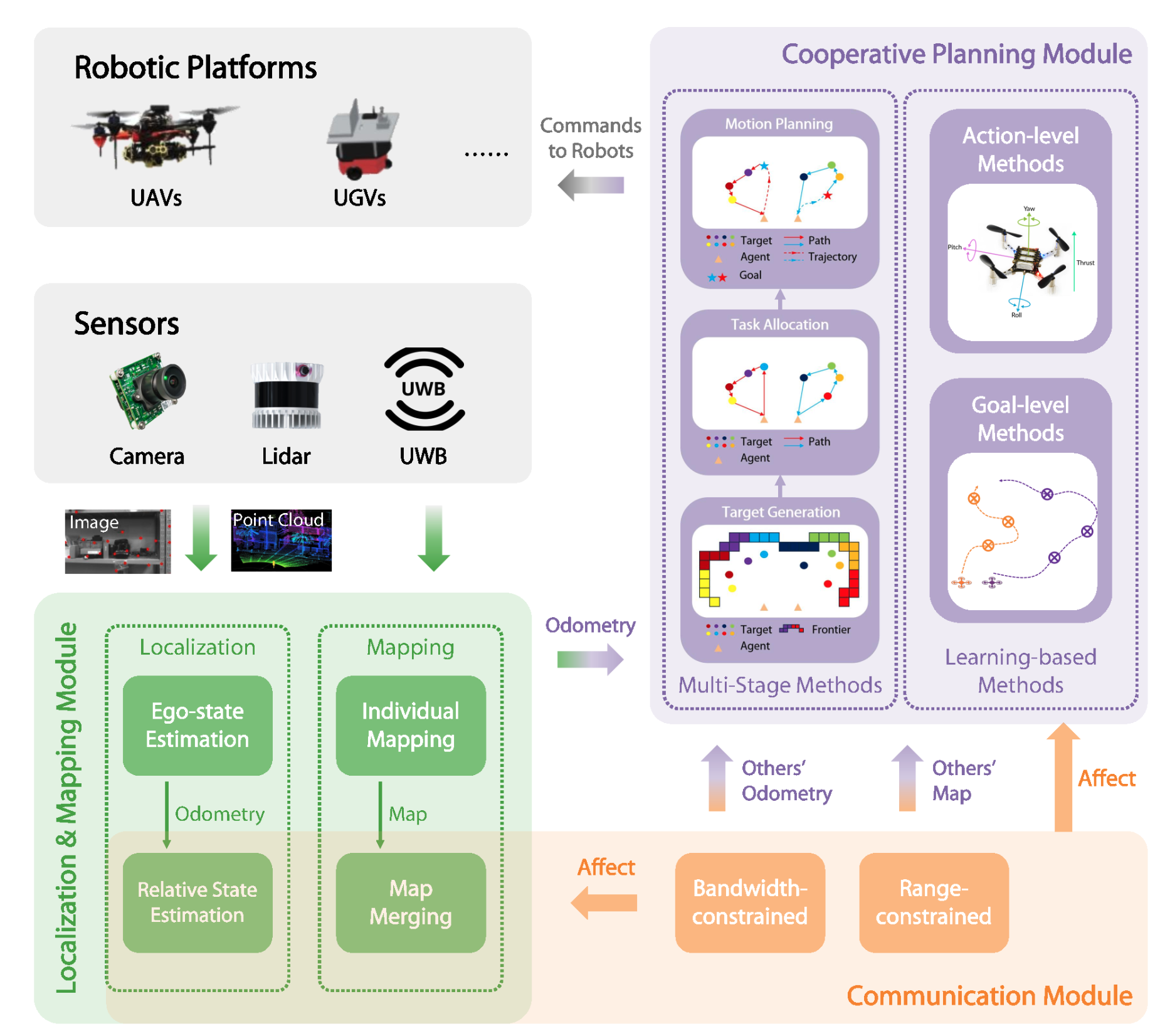
Multi-Robot System for Cooperative Exploration in Unknown Environments: A Survey
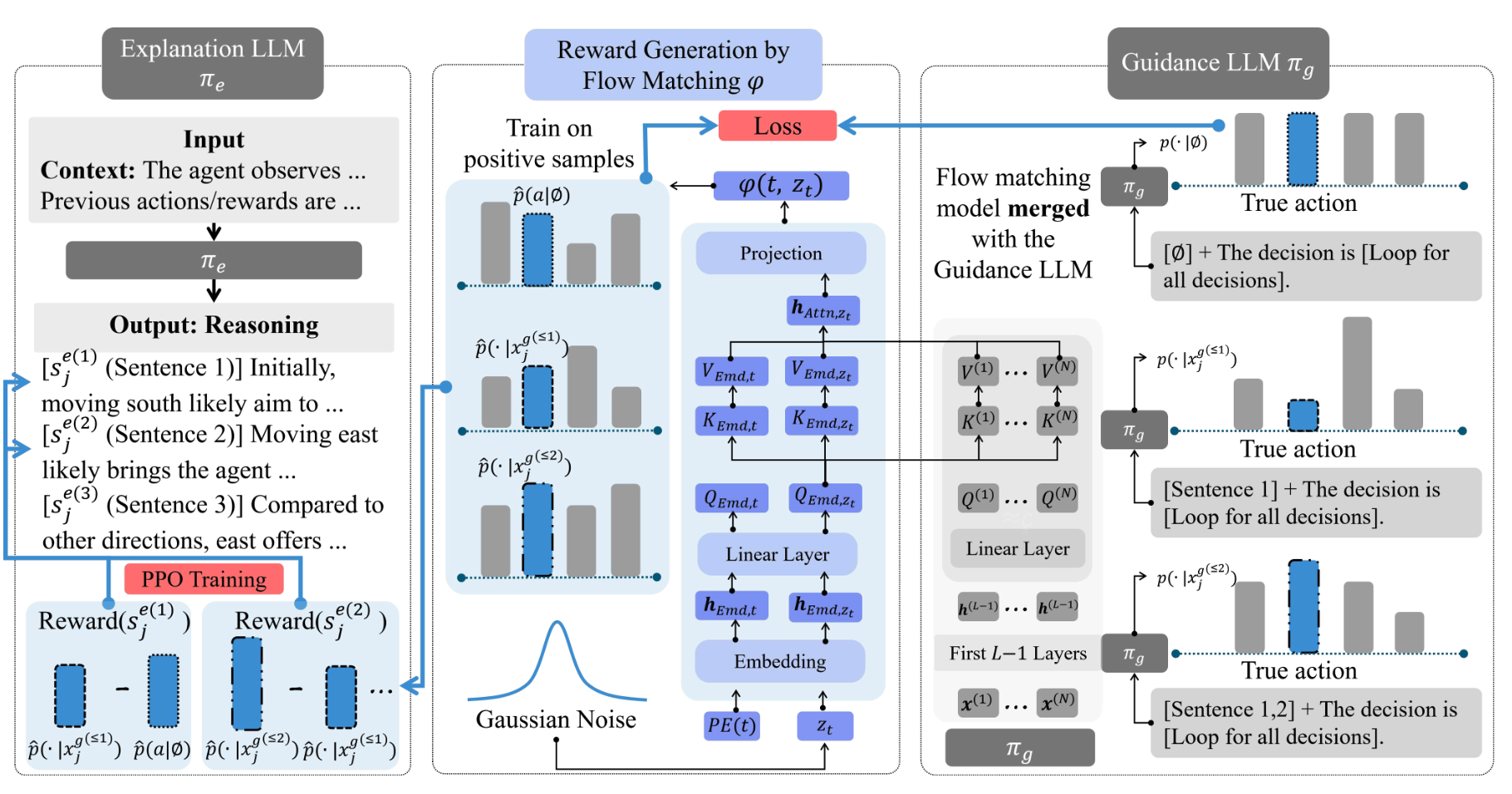
Translate Policy to Language: Flow Matching Generated Rewards for LLM Explanations
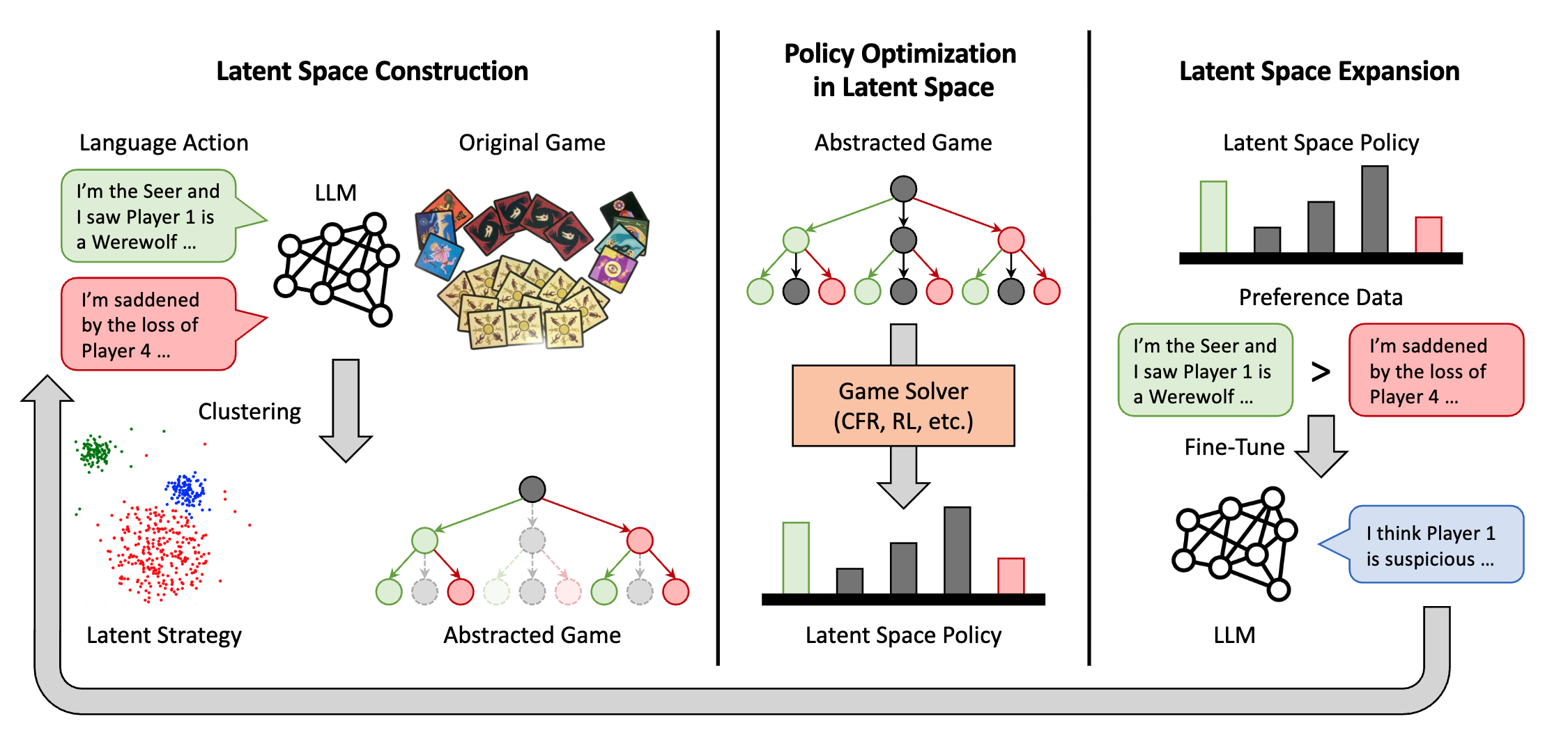
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
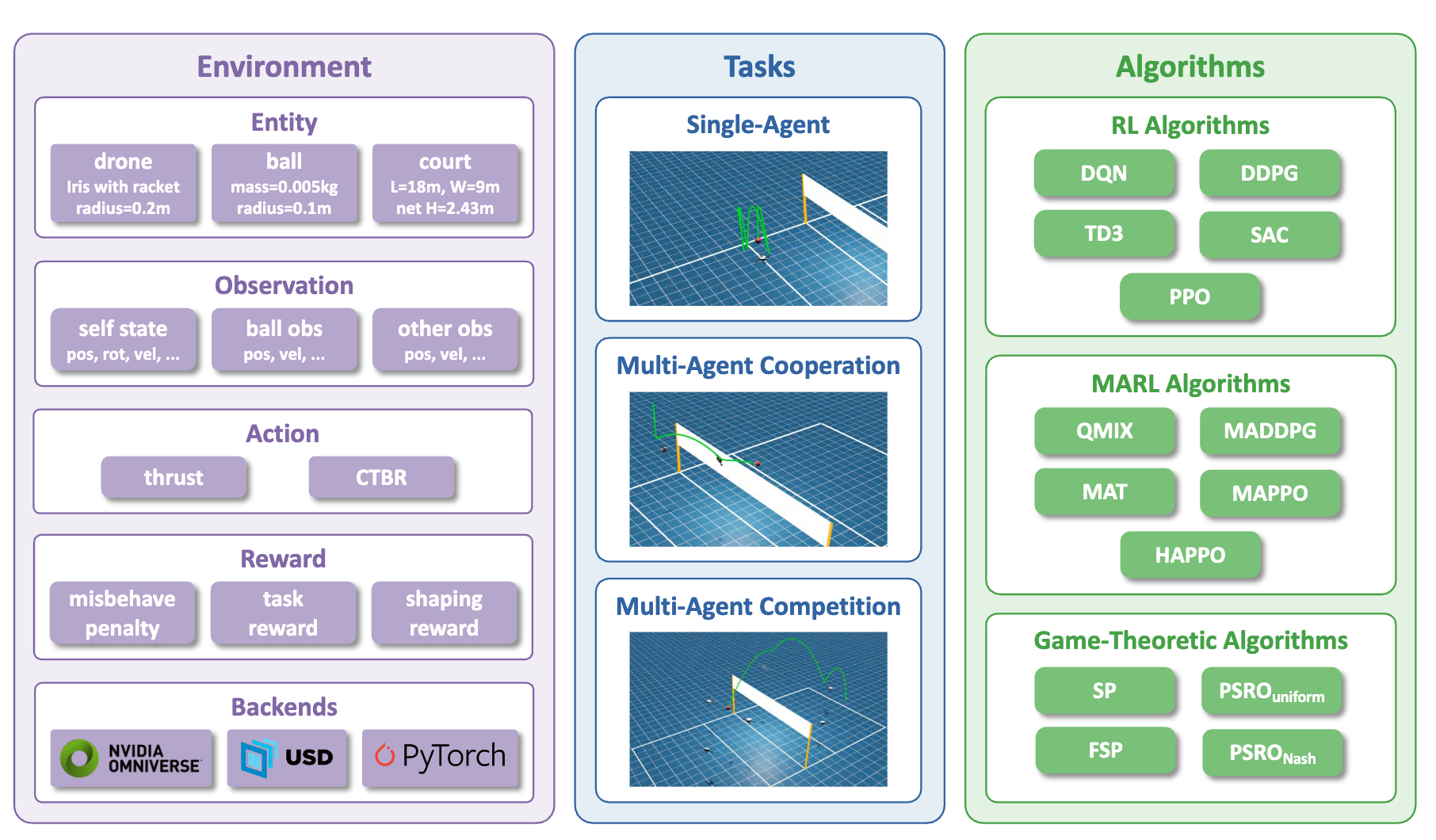
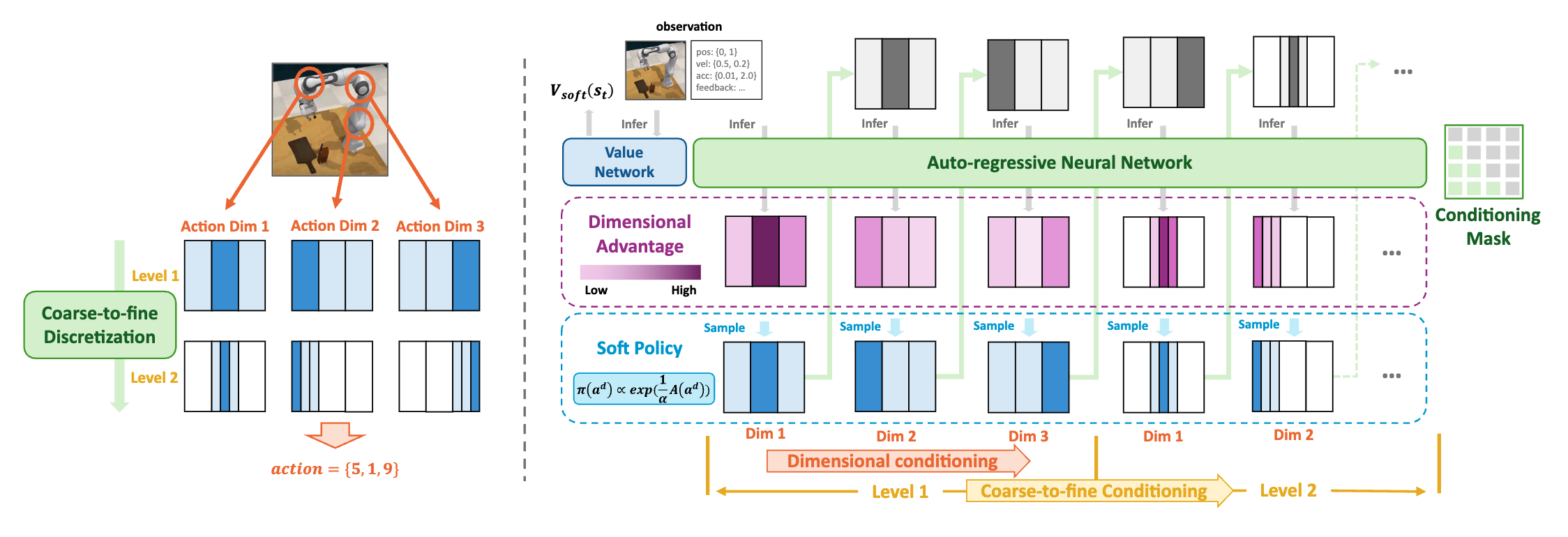
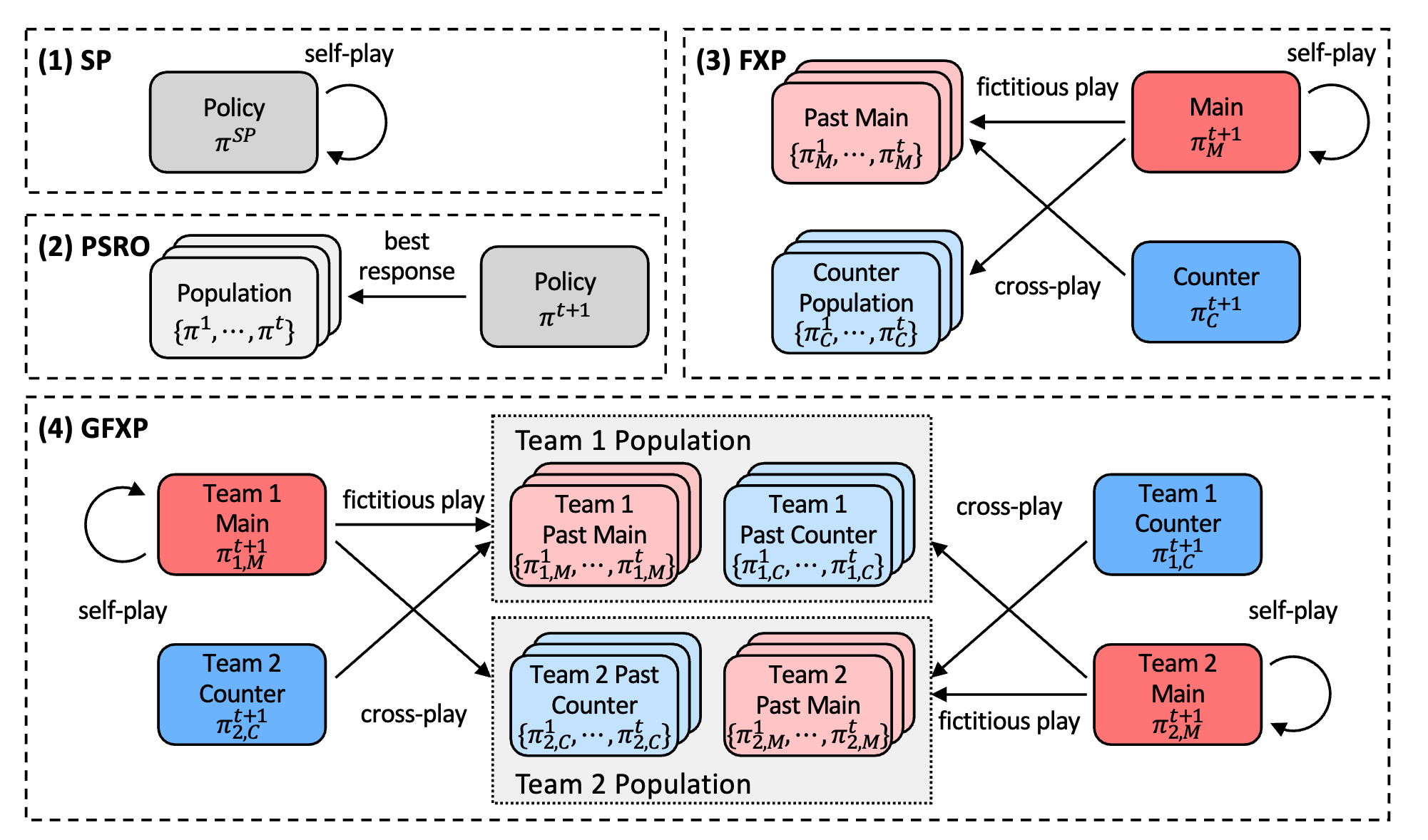
Learning Global Nash Equilibrium in Team Competitive Games with Generalized Fictitious Cross-Play
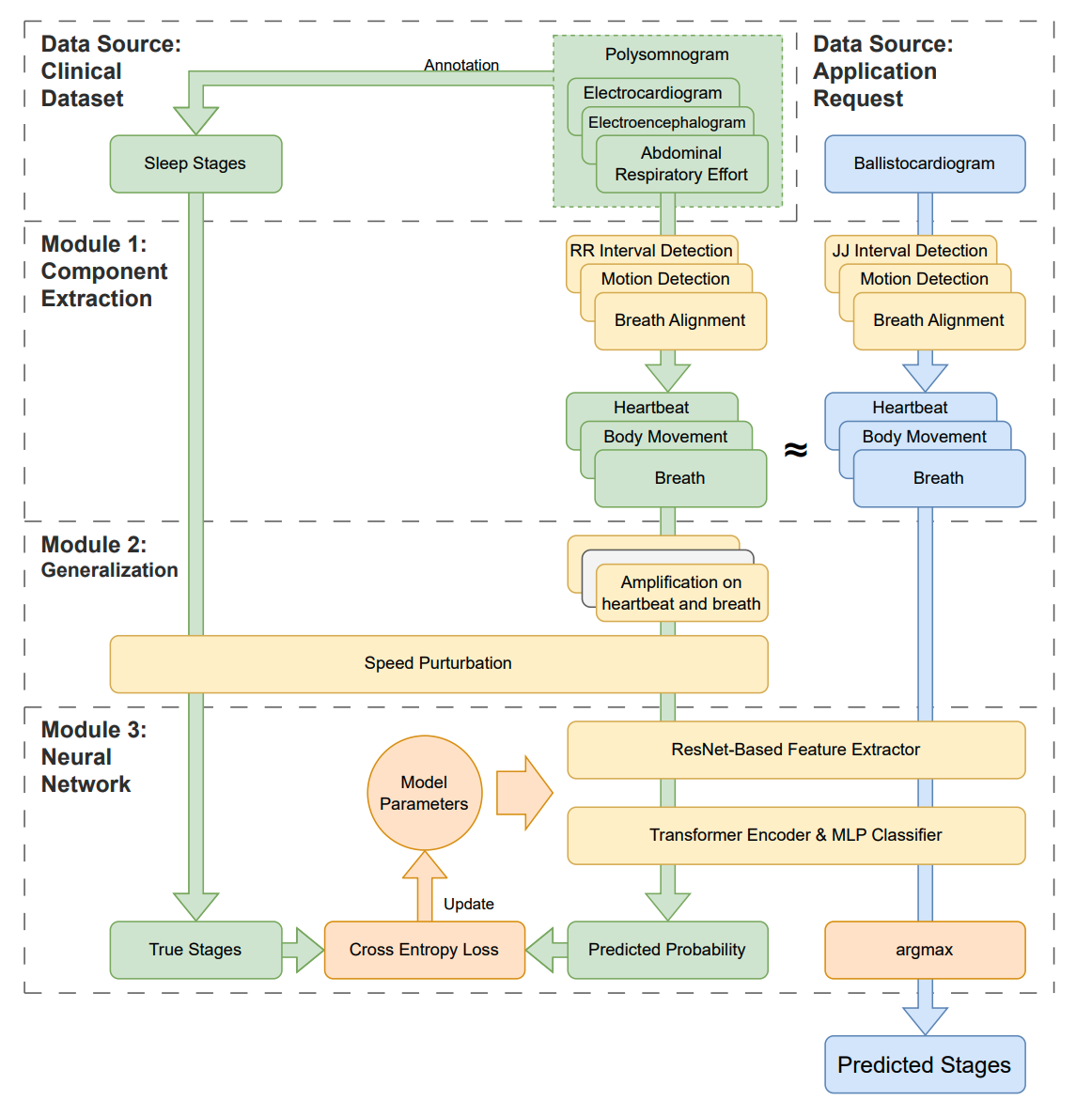
SleepNetZero: Zero-Burden Zero-Shot Reliable Sleep Staging with Neural Networks Based on Ballistocardiograms
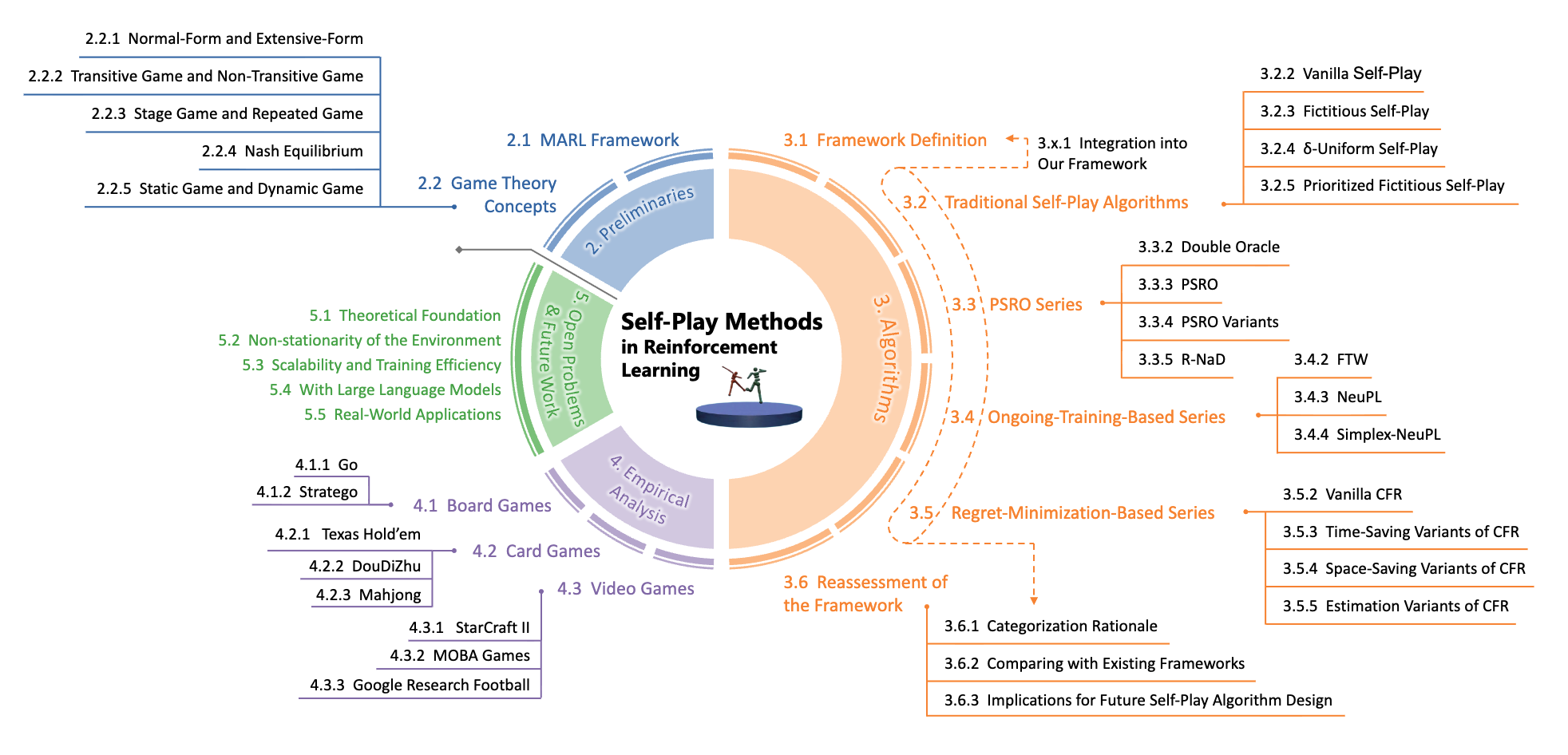
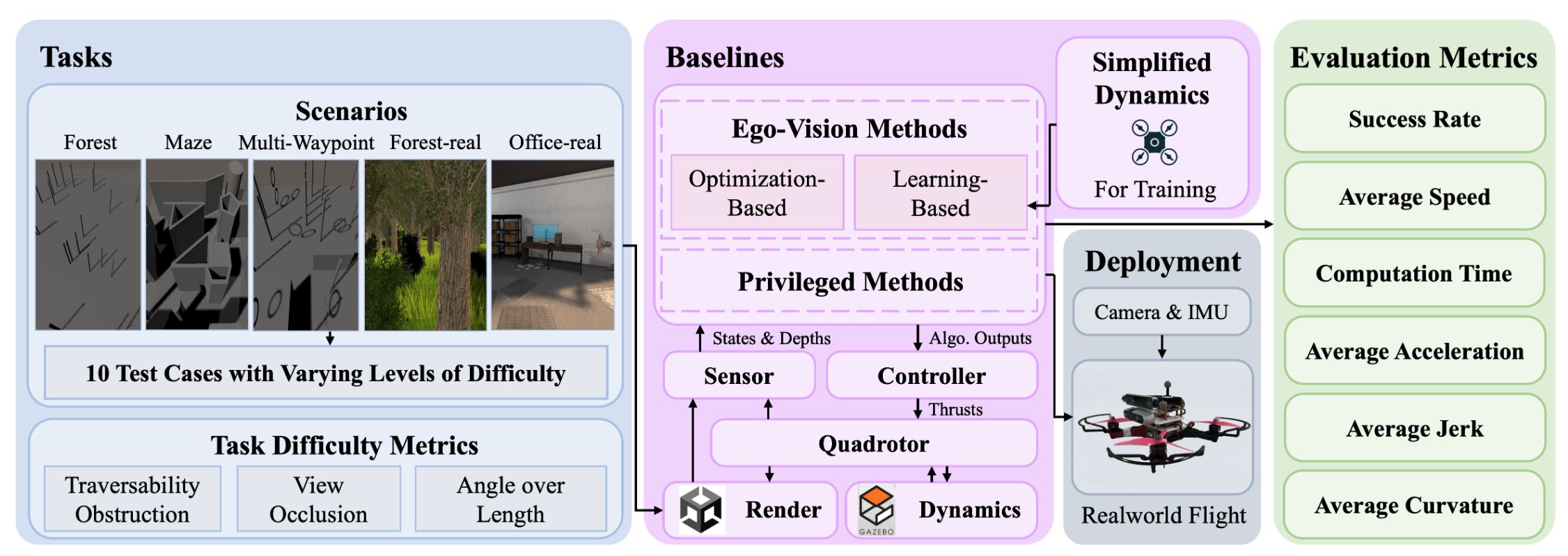
FlightBench: A Comprehensive Benchmark of Spatial Planning Methods for Quadrotors
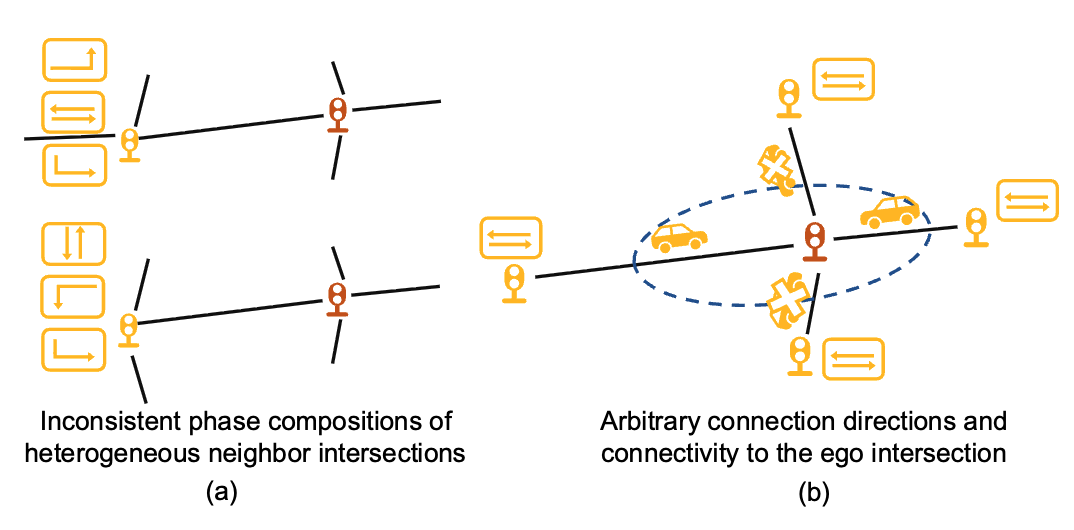
CityLight: A Universal Model Towards Real-world City-scale Traffic Signal Control Coordination
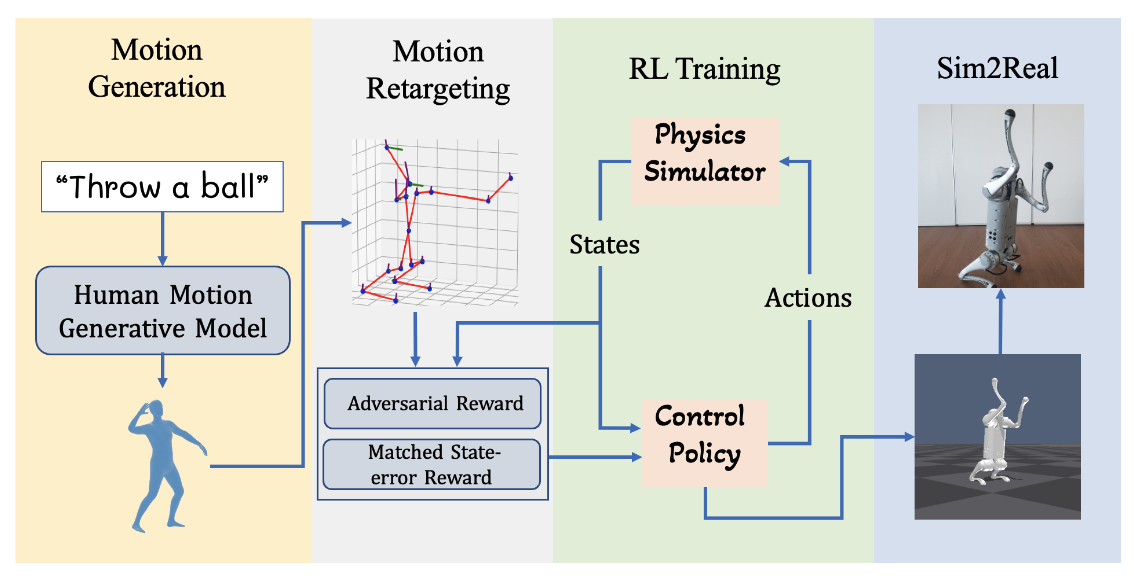
LAGOON: Language-Guided Motion Control
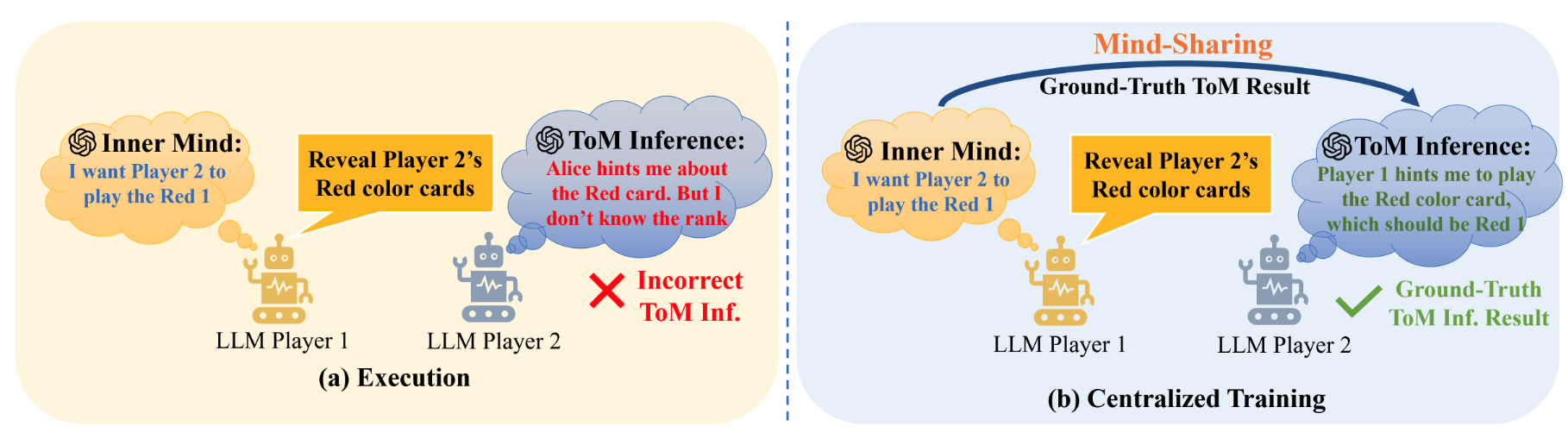
Sharing Minds during MARL Training for Enhanced Cooperative LLM Agents
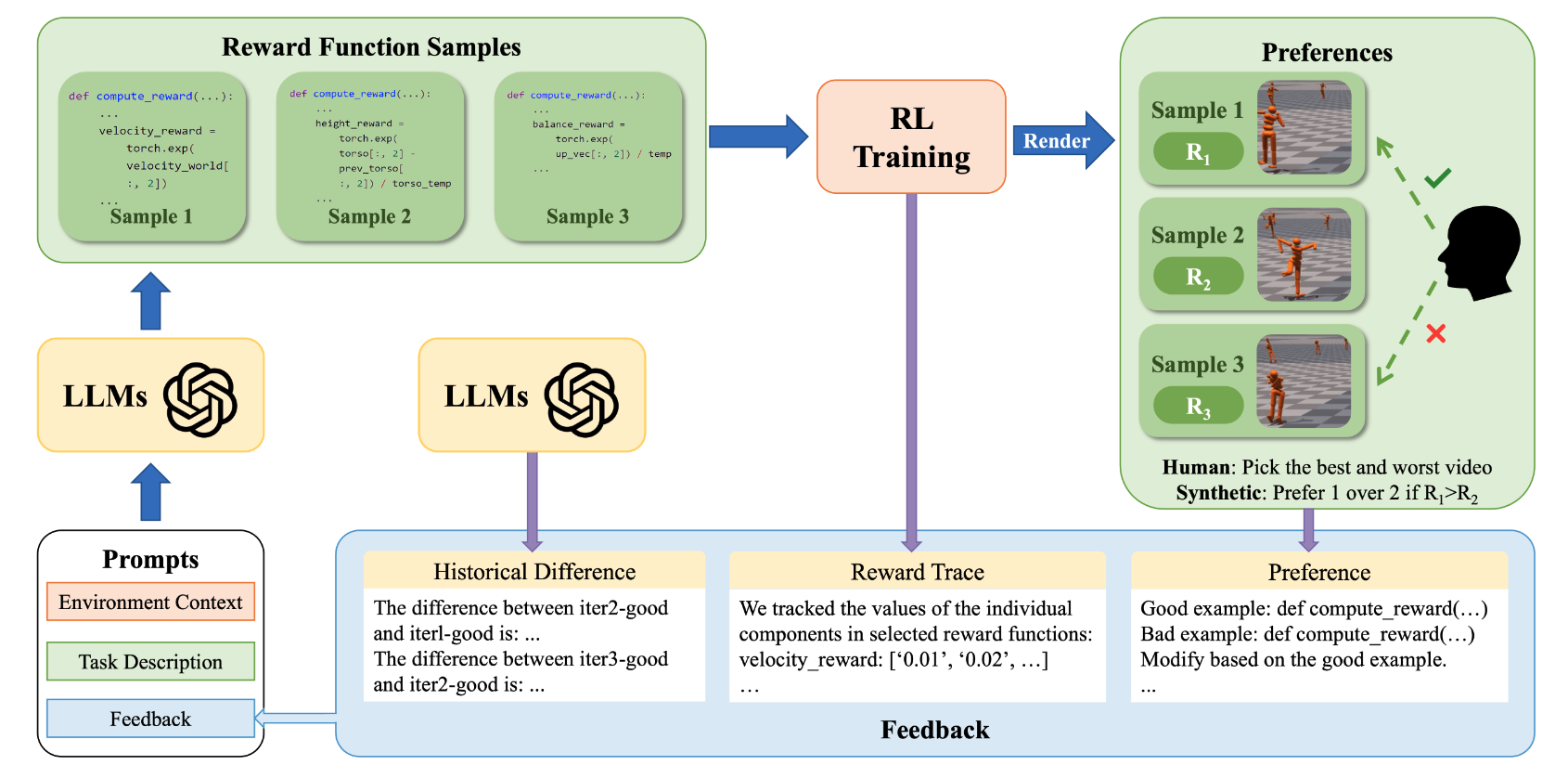
Few-shot In-context Preference Learning using Large Language Models
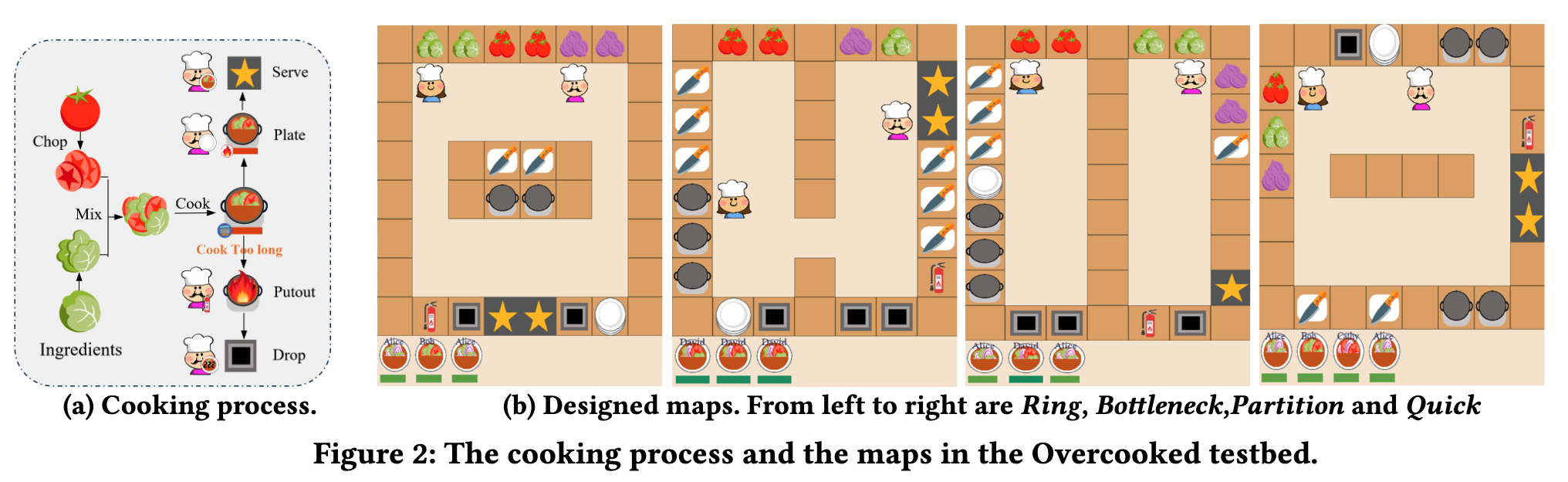
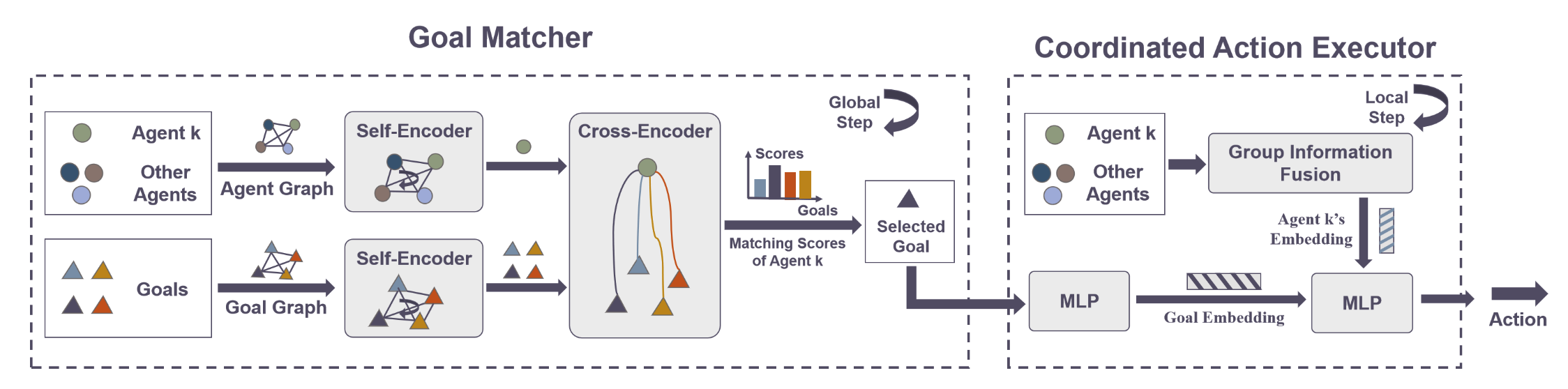
LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination
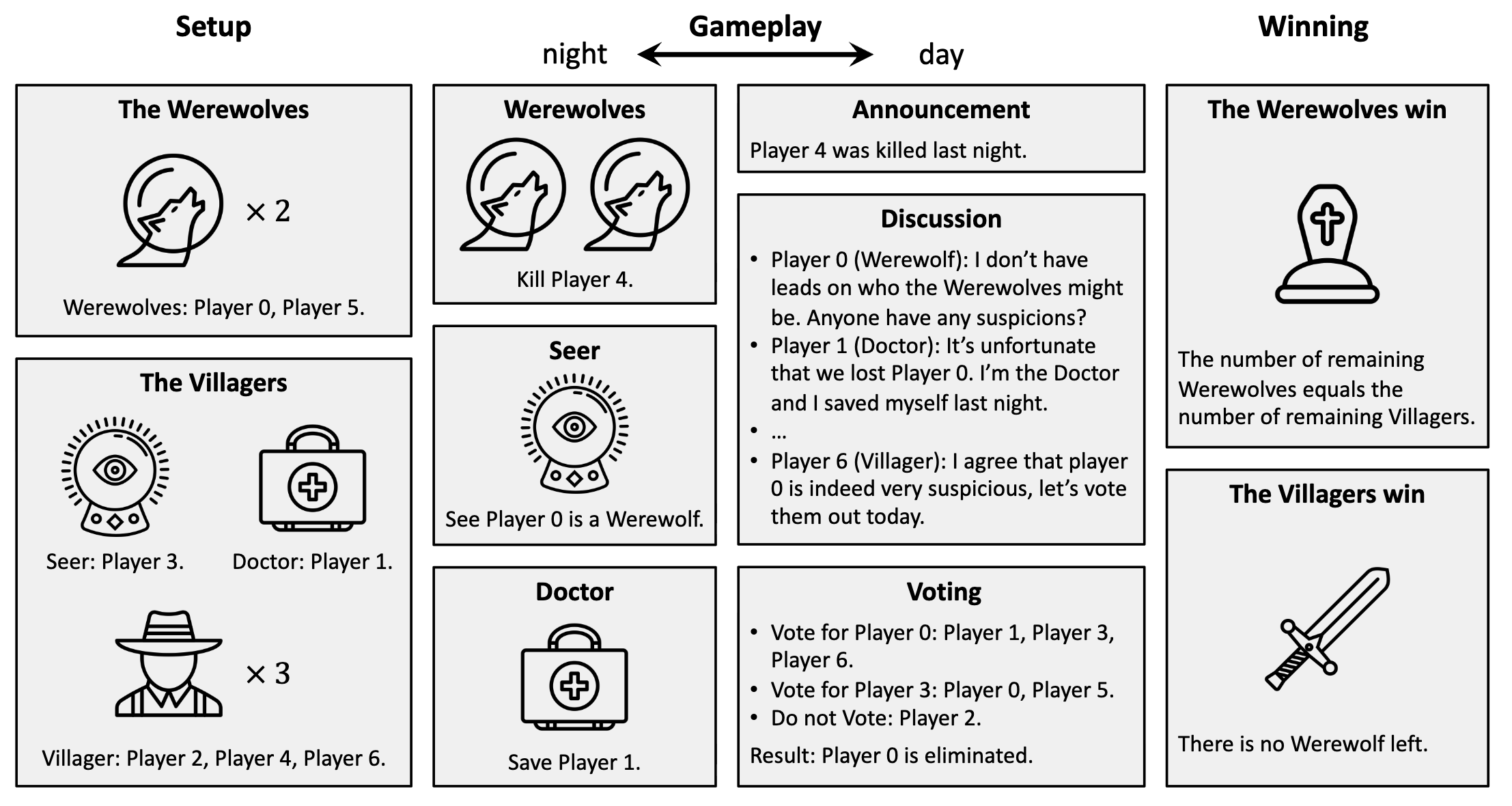
Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game
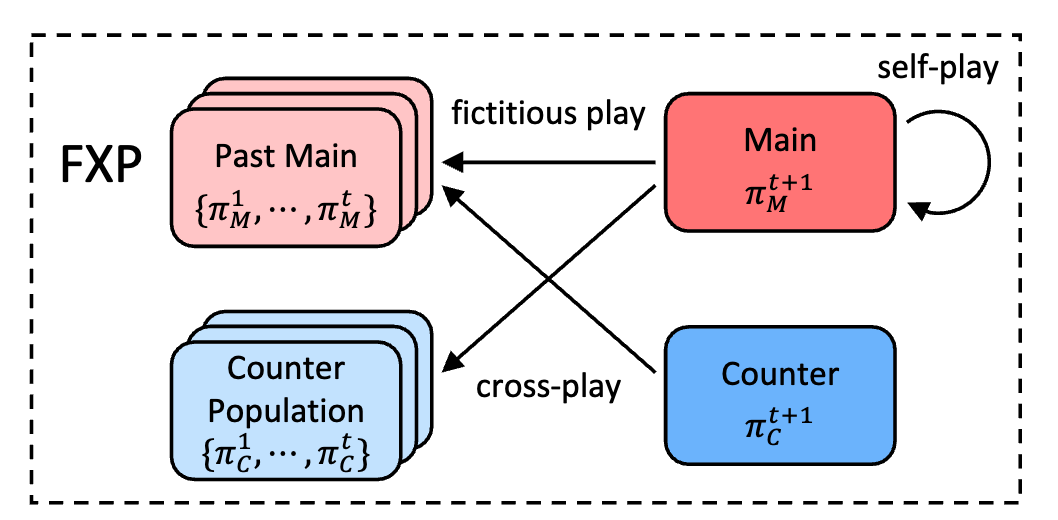
Fictitious Cross-Play: Learning Global Nash Equilibrium in Mixed Cooperative-Competitive Games

Learning Zero-Shot Cooperation with Humans, Assuming Humans Are Biased
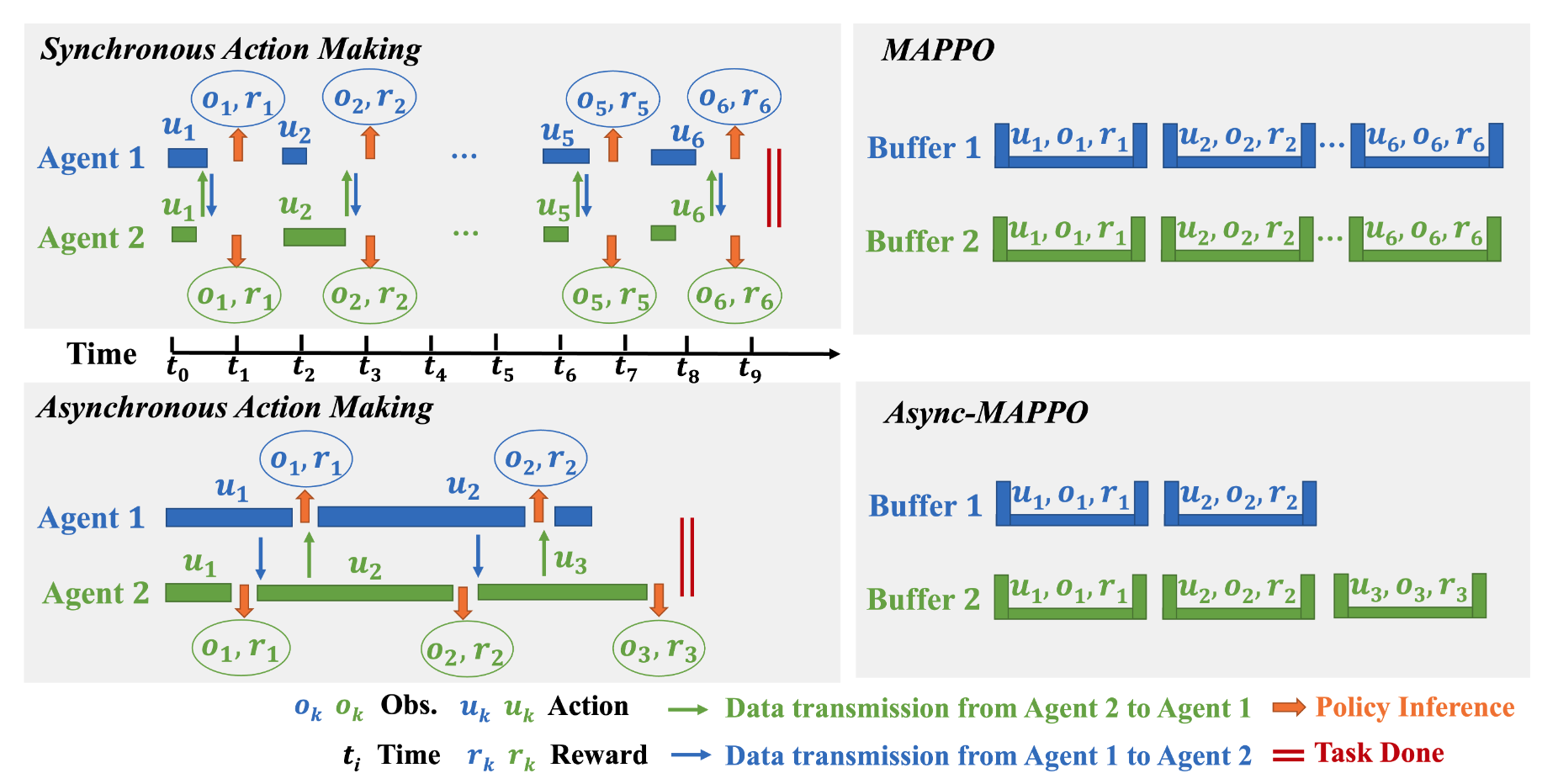
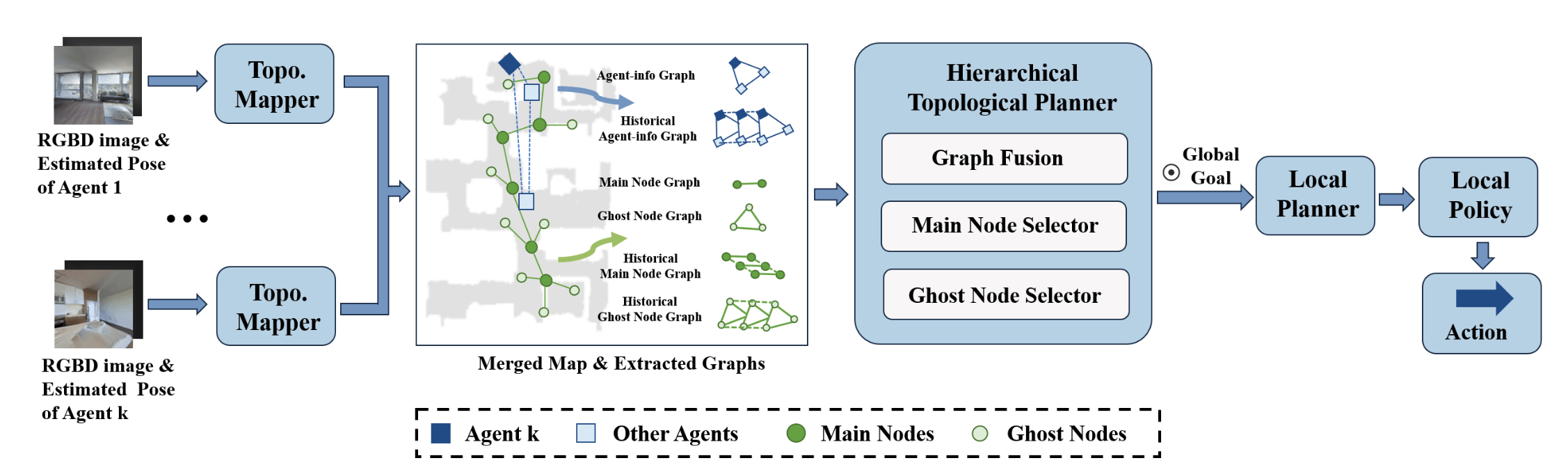
Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
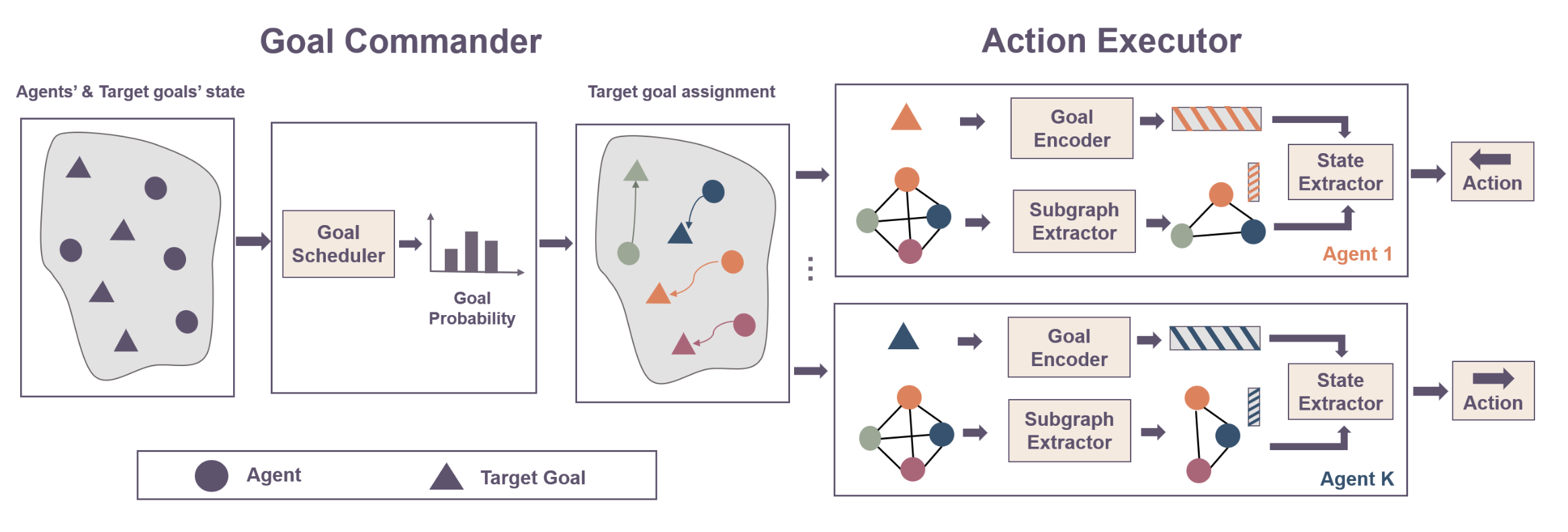
Learning Graph-Enhanced Commander-Executor for Multi-Agent Navigation
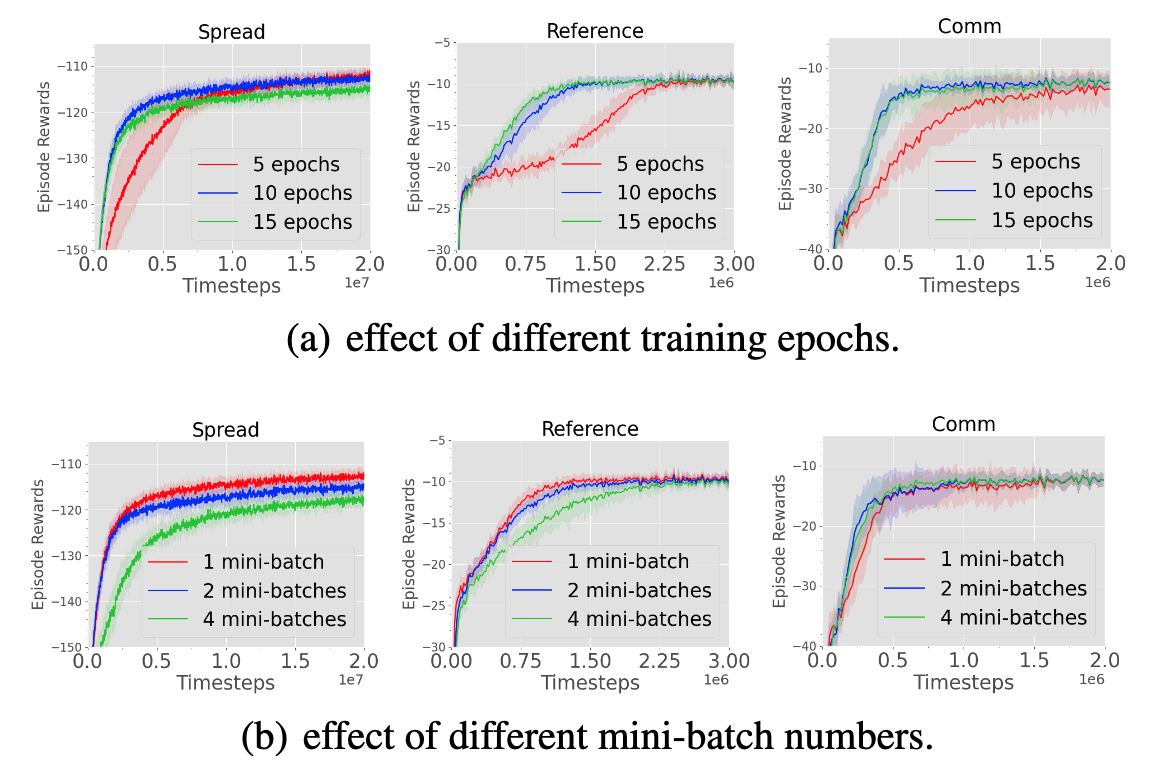
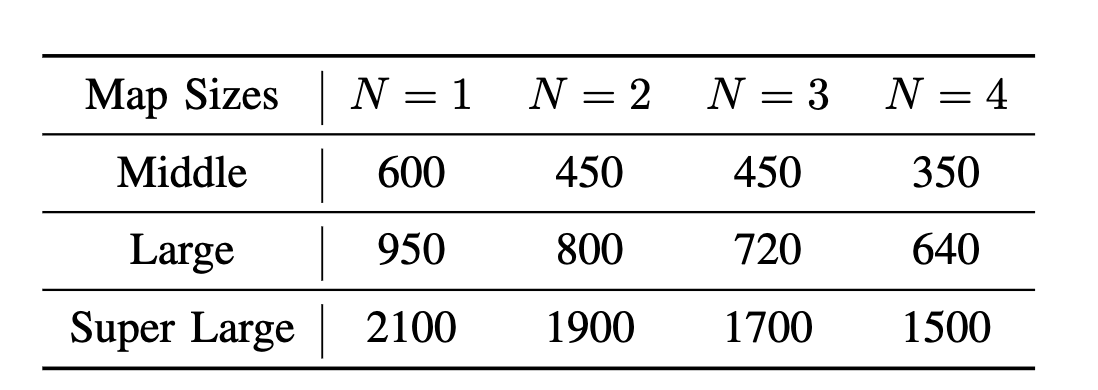
A Benchmark of Planning-based Exploration Methods in Photo-Realistic 3D Simulator
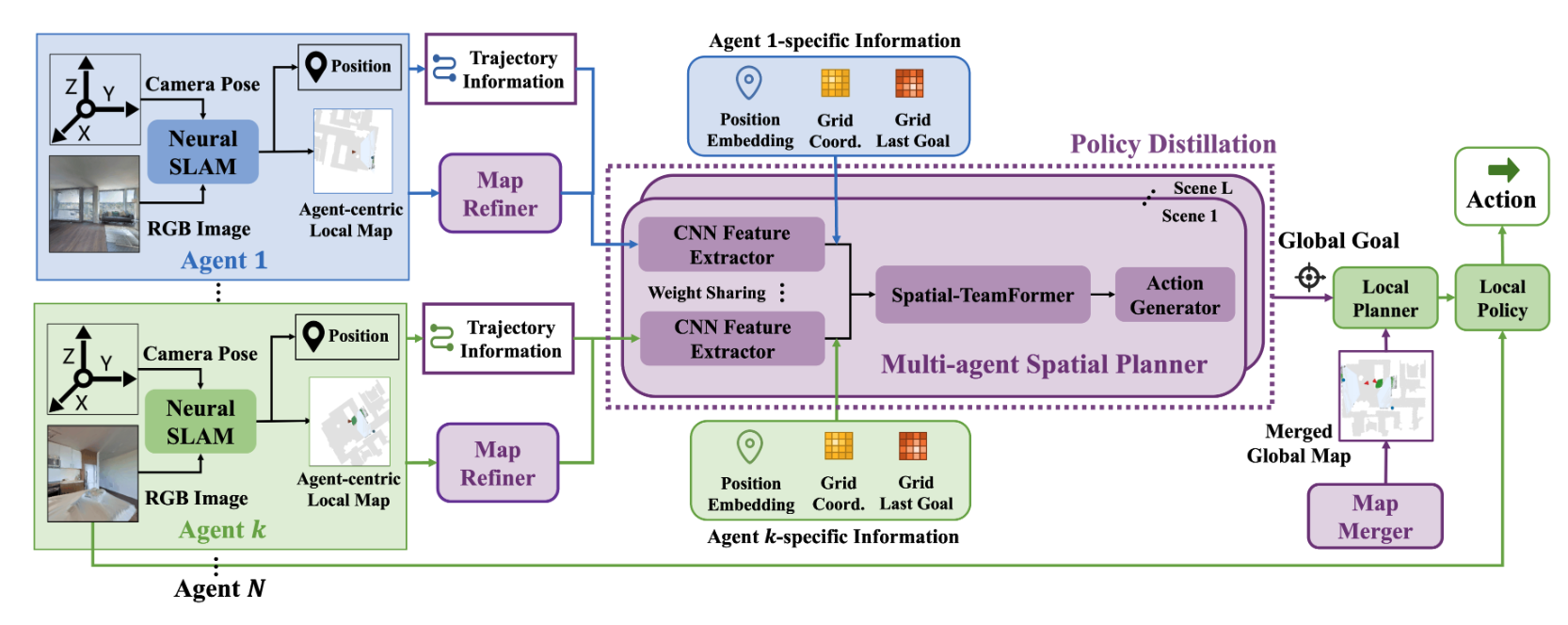
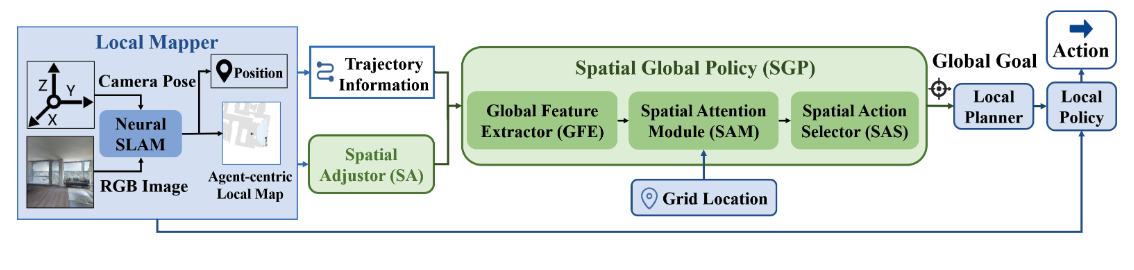
SAVE: Spatial-Attention Visual Exploration
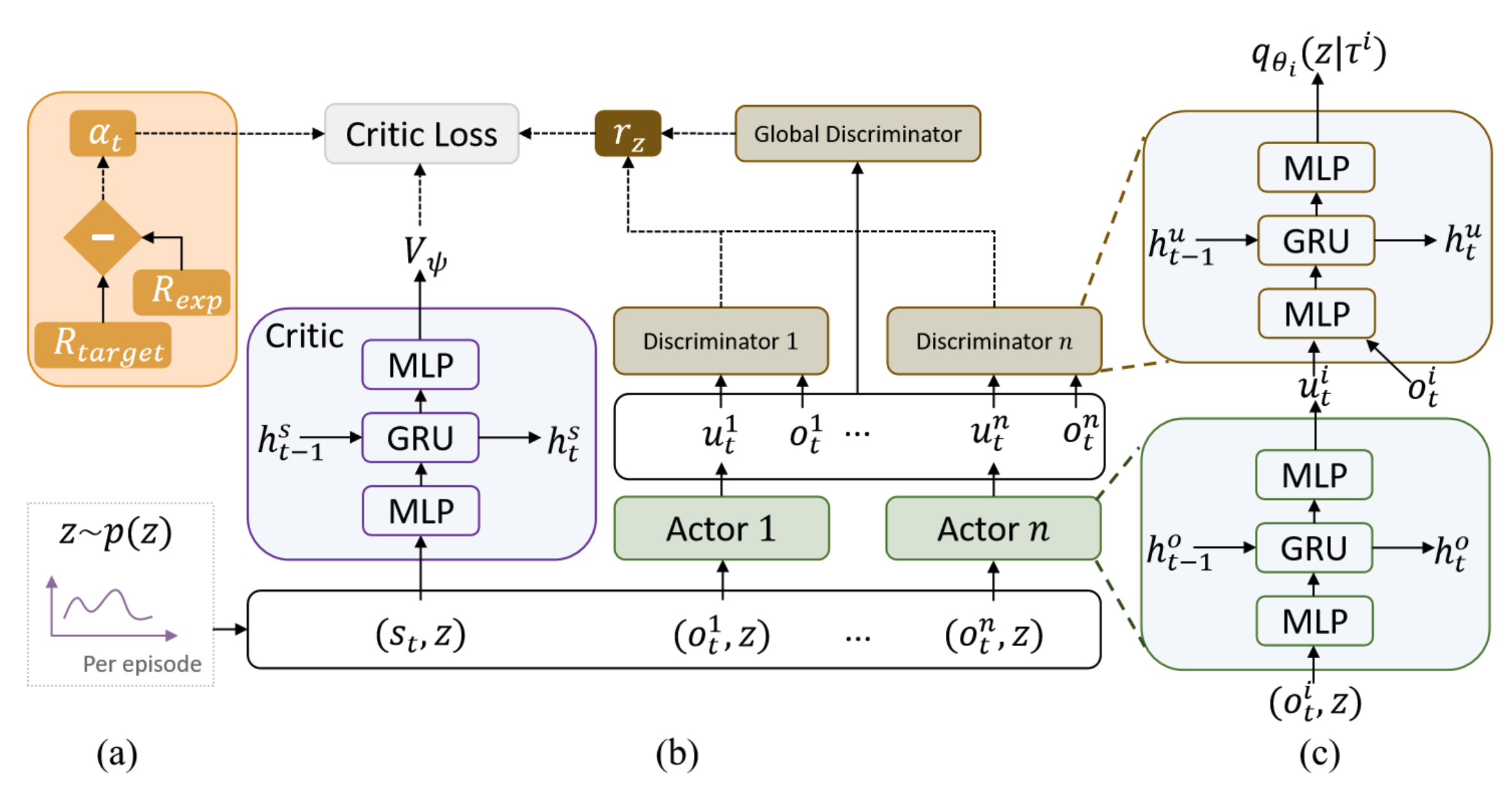
VMAPD: Generate Diverse Solutions for Multi-Agent Games with Recurrent Trajectory Discriminators

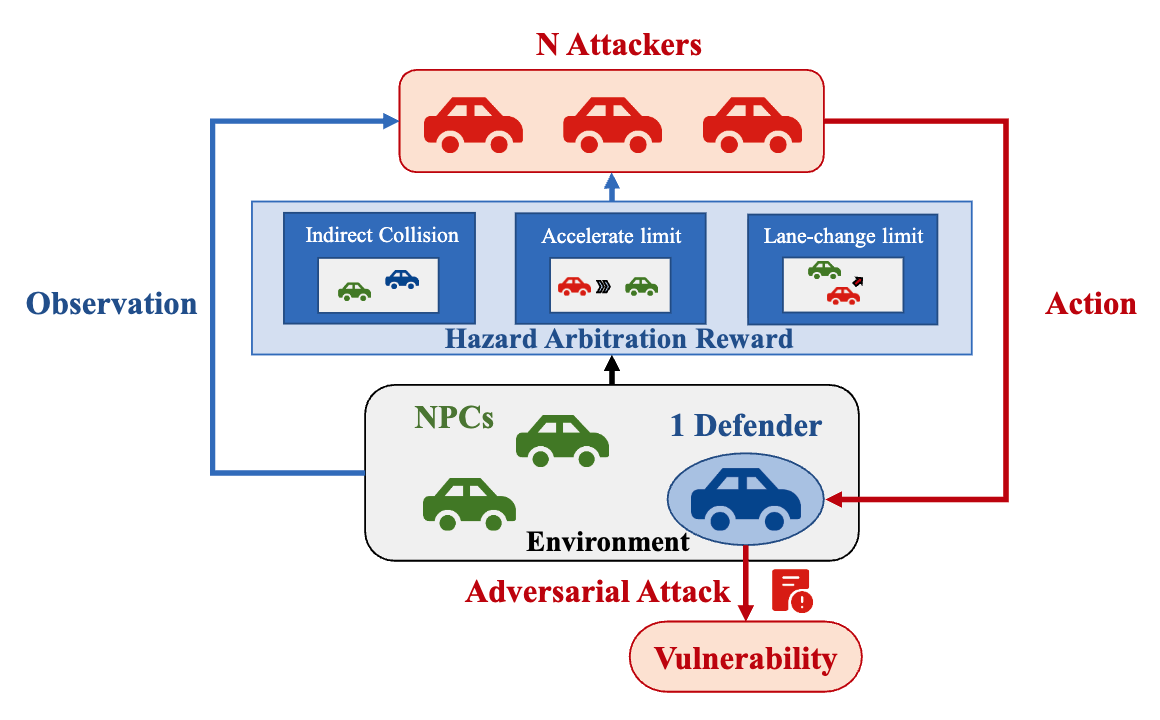
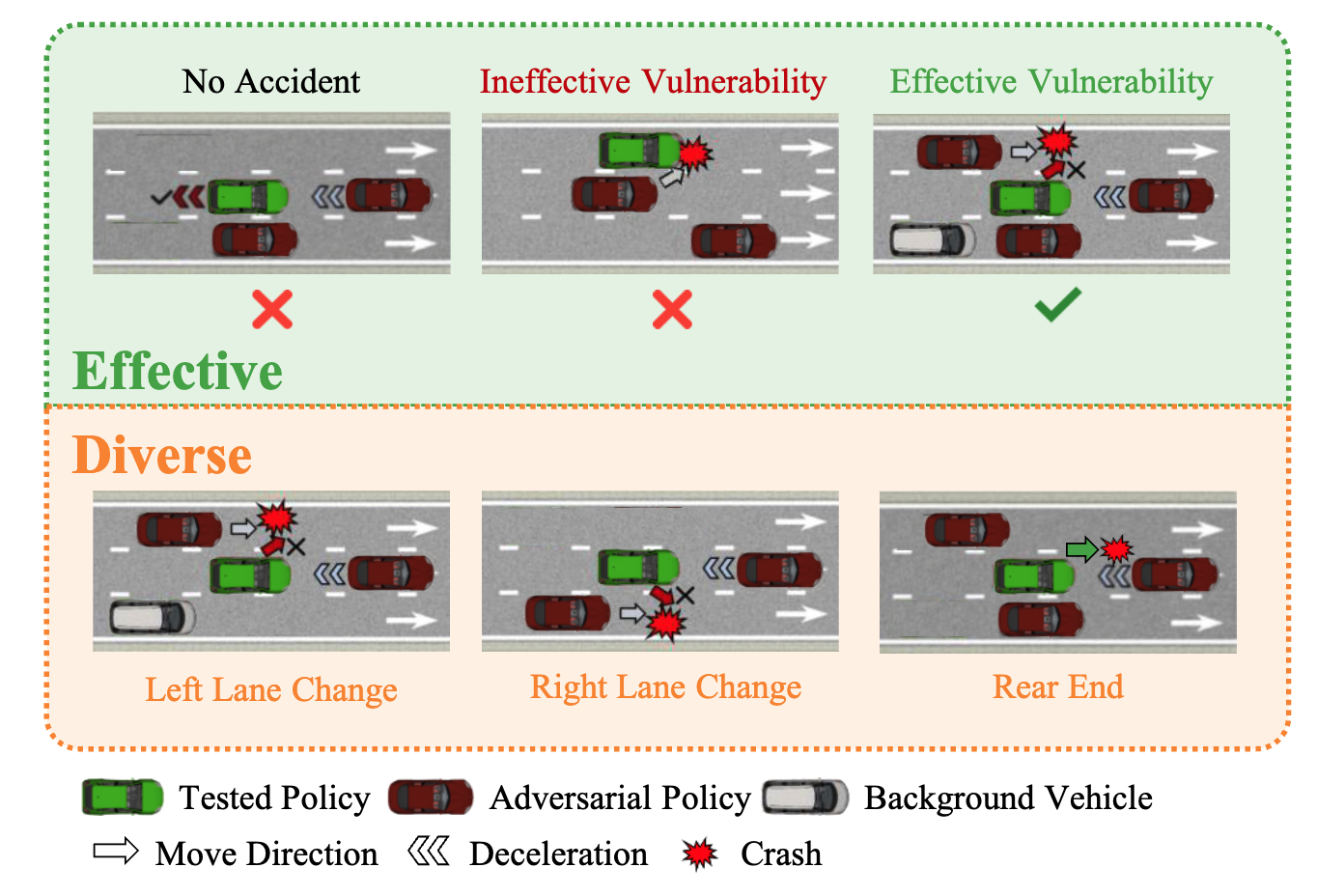
Multi-Agent Vulnerability Discovery for Autonomous Driving with Hazard Arbitration Reward

Unlocking the Potential of MAPPO with Asynchronous Optimization
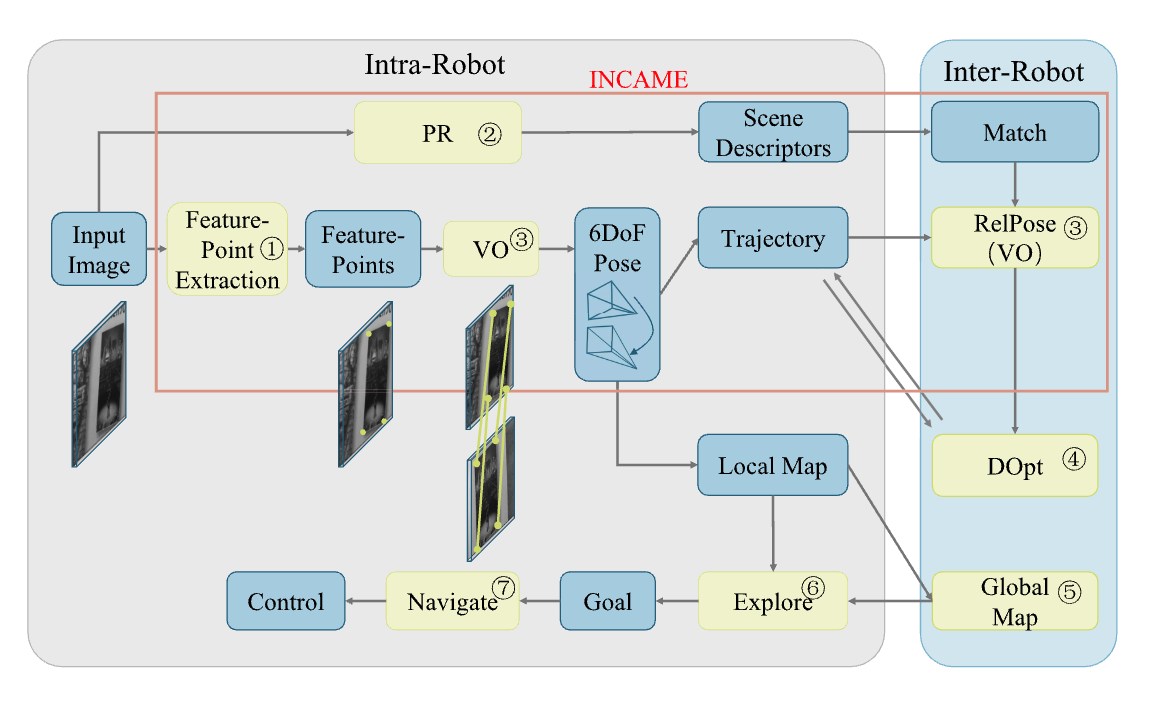
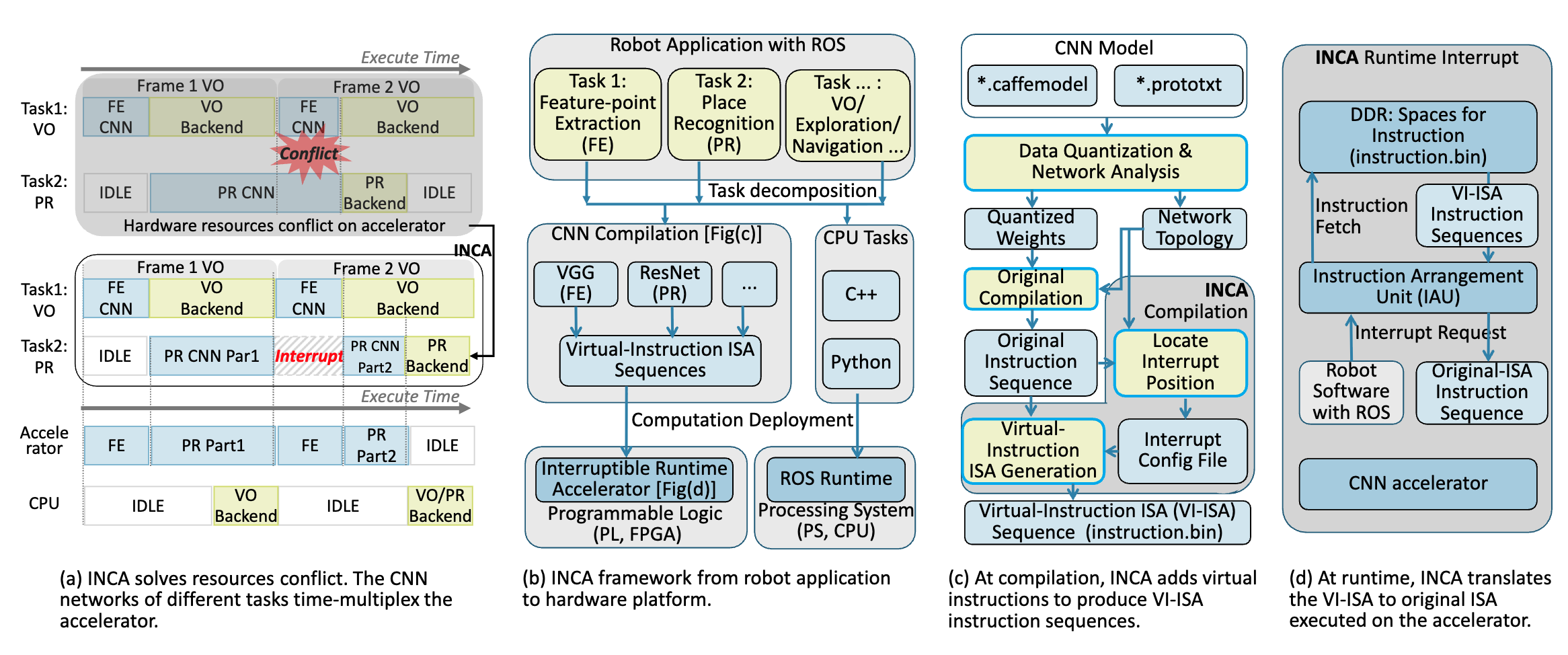
INCA: INterruptible CNN Accelerator for Multi-tasking in Embedded Robots
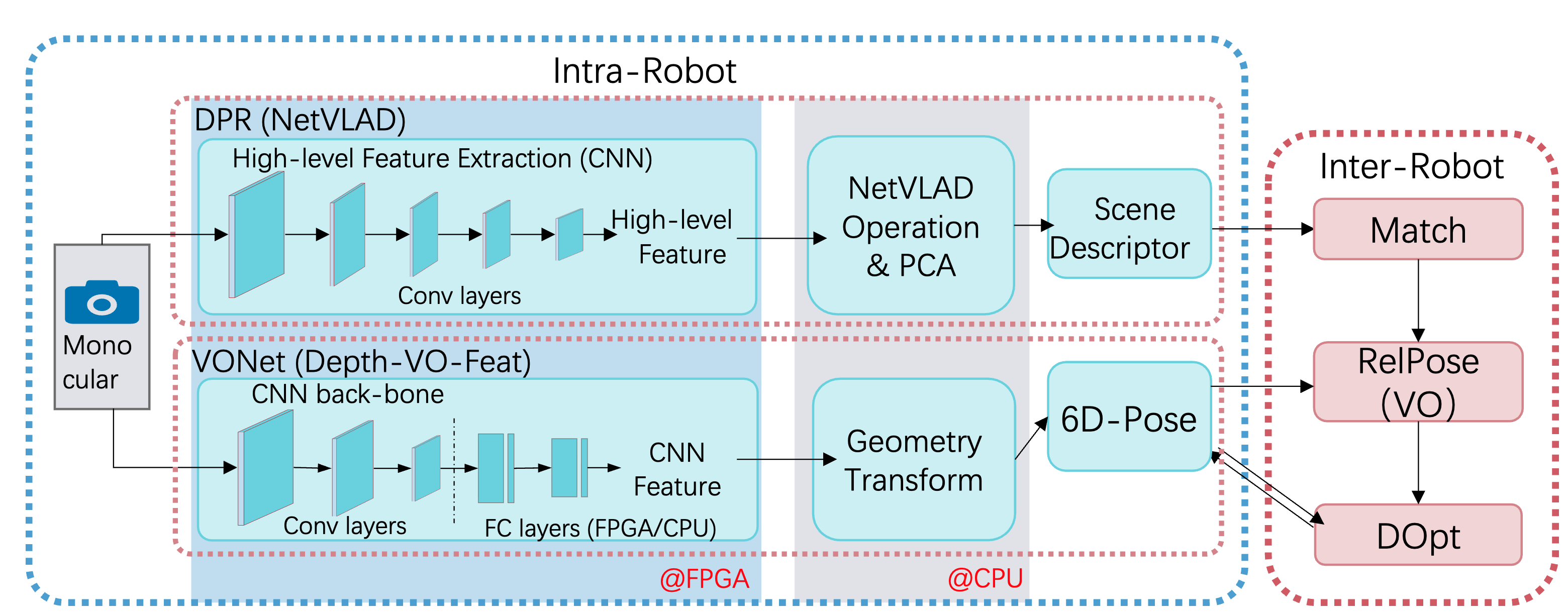
CNN-based Monocular Decentralized SLAM on Embedded FPGA
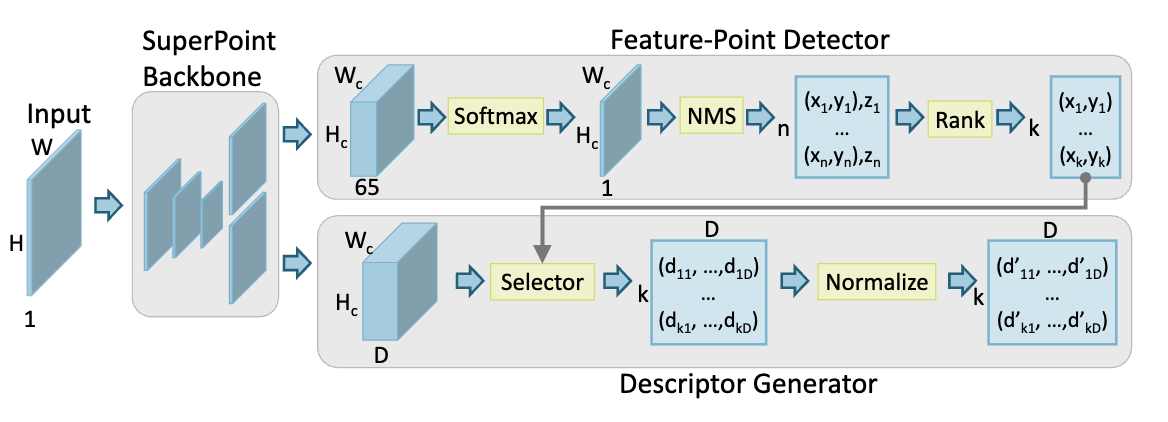
CNN-based Feature-point Extraction for Real-time Visual SLAM on Embedded FPGA
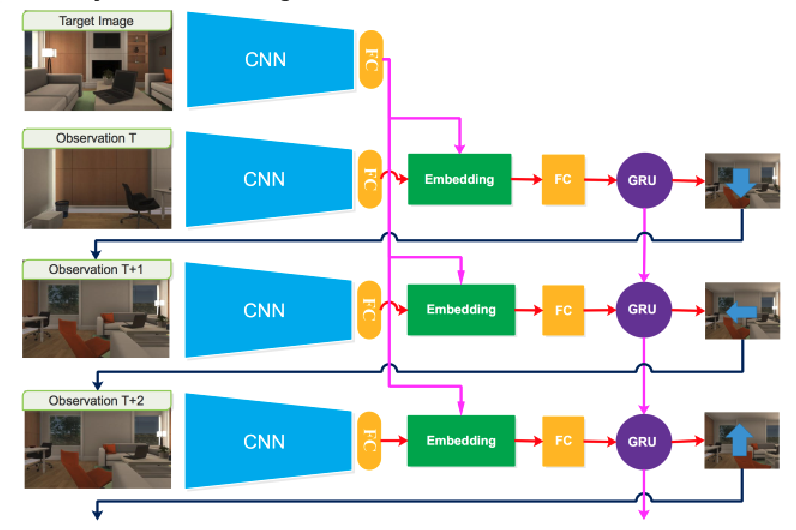
Long-Sighted Imitation Learning for Partially Observable Control
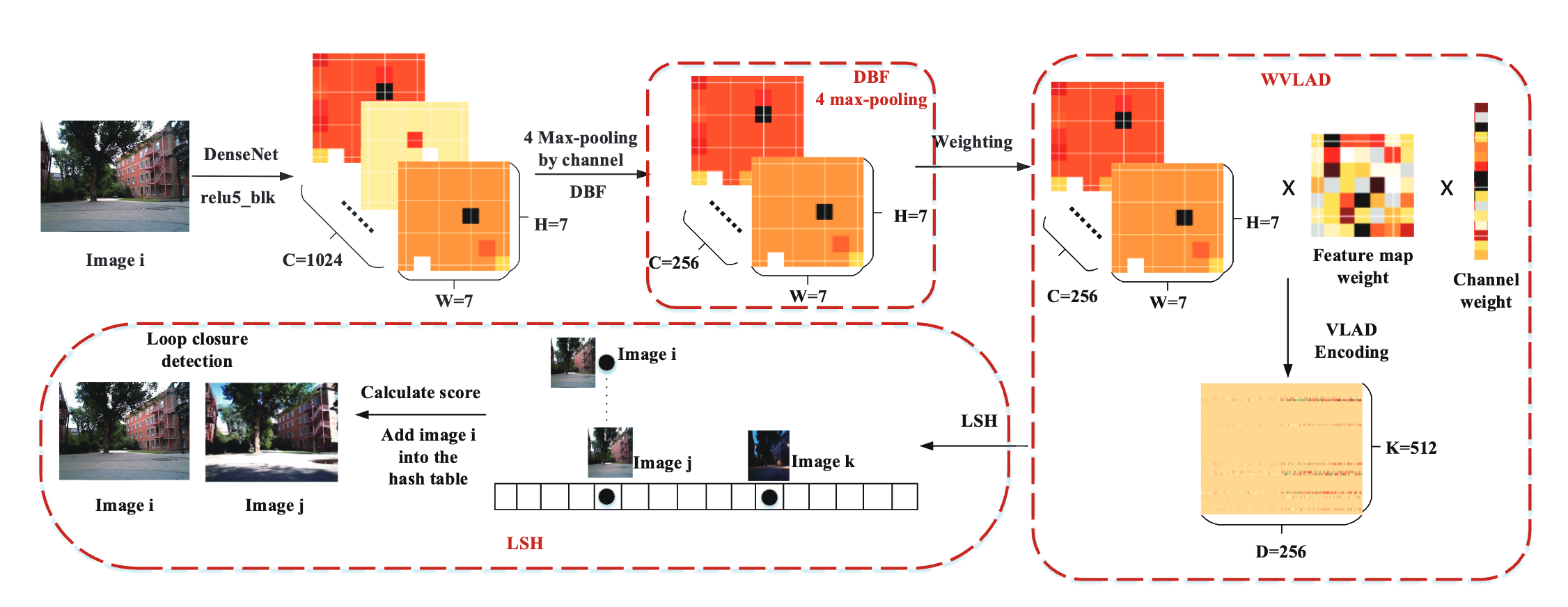
A DenseNet Feature-based Loop Closure Method for Visual SLAM System
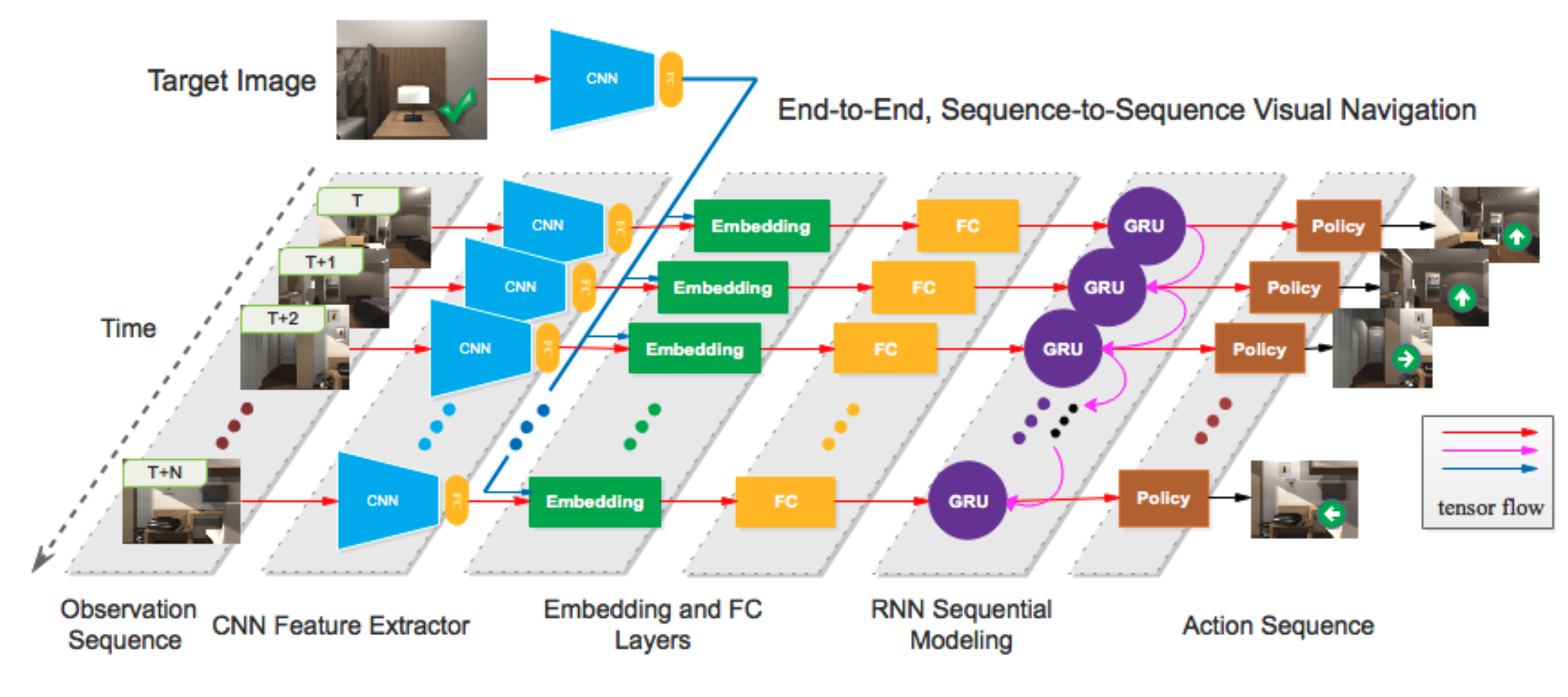
Learning Safety-Aware Policy with Imitation Learning for Context-Adaptive Navigation
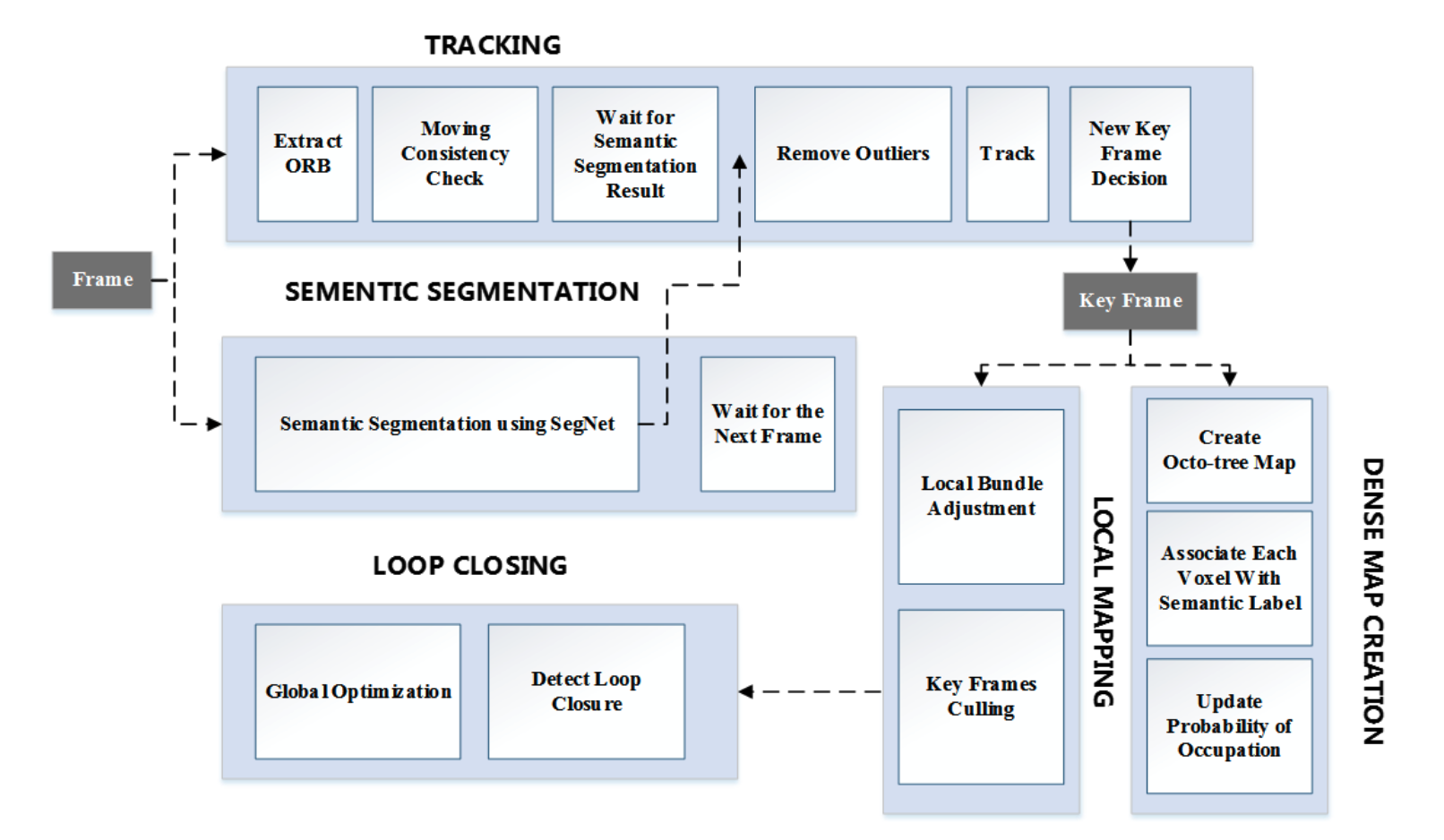
DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments
🏆 Awards
- 2024: China Postdoctoral Excellent Special Foundation (Top 1,000 nationwide), Chinese Postdoctoral Science Foundation (CPSF).
- 2024: Postdoctoral Fellowship Program (Top 3,000 nationwide), Chinese Postdoctoral Science Foundation (CPSF).
- 2024: Runner-up for Outstanding Doctoral Thesis (Top 5), Chinese Intelligent Agent and Multi-Agent Systems.
- 2023: Shuimu Scholar Program, Tsinghua University.
- 2023: Chuanxin Future Scholar Program, Department of Electronic Engineering, Tsinghua University.
- 2023: Zhang Keqian Postdoctoral Fellowship, Department of Electronic Engineering, Tsinghua University.
- 2023: Outstanding Doctoral Thesis (Top 10%), Tsinghua University.
- 2023: Outstanding Doctoral Graduate (Top 5%), Tsinghua University.
- 2019: Outstanding Master’s Thesis (Top 10%), Tsinghua University.
- 2019 - 2023: First-Class Scholarship (3 times), Tsinghua University.
- 2015: National Scholarship, China Ministry of Education.
🎤 Talks

RLinf: A Highly Flexible Reinforcement Learning Post-Training Framework for Embodied Intelligence

👓 Projects
- Projects: [1] 基于深度强化学习的多无人机追逃博弈决策和控制关键技术研究,国家自然科学基金委,青年科学基金项目(C类), 2025-2027.
- Projects: [2] 多机协同高效机器学习系统研究,国家自然科学基金-中德合作交流基金, 2021-2025.
- Projects: [3] 具有强推理能力的大语言模型智能体关键技术研究,中国博士后基金特别资助, 2023-2025.
💼 Work Experience
- 2026.01 - Present: Assistant Professor, Tsinghua University.
- 2023.07 - 2025.12: Postdoctoral Researcher, Tsinghua University.
🙋 Recruitment
We are actively recruiting!
We are looking for Ph.D. and Master students, Postdocs at Tsinghua University, Ph.D. students of the Joint Program of Zhongguancun Academy and Tsinghua University and Undergraduate Interns with strong interests and motivation to work on frontier research topics including:
Candidates with hands-on systems building abilities and mathematical background are highly encouraged.
🔗 Bond